How to Scale an App to 10 Million Users on AWS: A Practical, Architecture-Driven Blueprint

- Published on
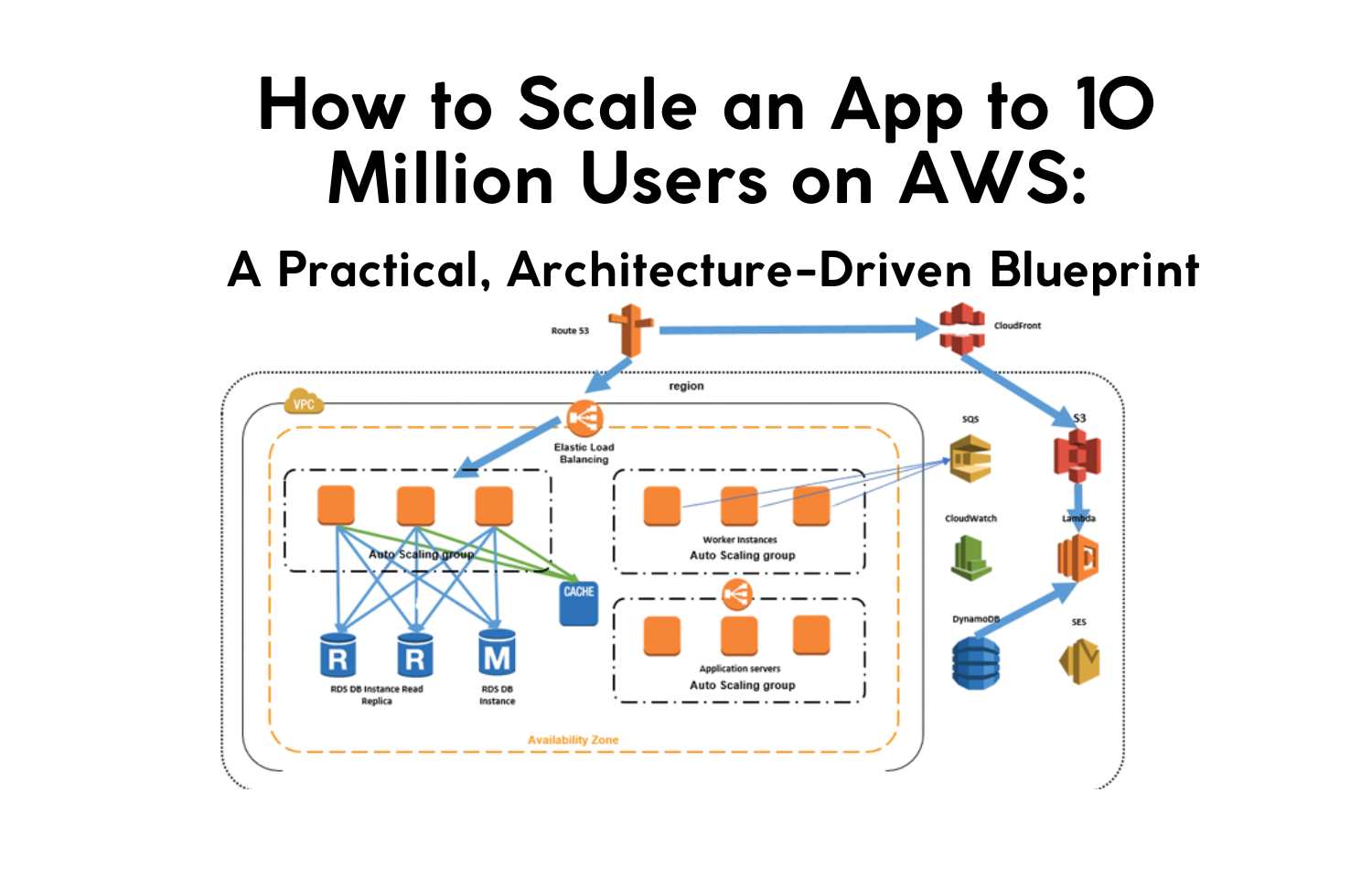
Scaling an application to 10 million users requires more than throwing hardware at the problem. Real-world large-scale systems demand intentional architecture, predictable performance modeling, intelligent caching, and cost-aware distributed design.
At JMS Technologies, we've built systems in FinTech, logistics, and large consumer applications that routinely operate under massive concurrency. In this guide, we break down the architecture, patterns, and AWS-native strategies required to reliably serve tens of thousands of requests per second.
This article is aimed at CTOs, staff engineers, and cloud architects who want a practical, field-tested blueprint for AWS-scale systems.
1. Why "10 Million Users" Must Be Quantified Before You Architect Anything
Teams often make the mistake of designing for total registered users instead of peak concurrent behavior. Scaling requires translating business goals into technical thresholds that map to AWS services.
The key numbers that actually define your architecture:
Peak Concurrent Users (PCU)
If 10M users yield ~5% peak concurrency:
~500,000 simultaneous sessions
This drives decisions around:
- autoscaling behavior
- load balancer capacity
- connection pooling
- cache design
Requests Per Second (RPS)
A typical mobile/web client sends 1–5 requests per minute.
This becomes:
500,000 active users → 8,000–20,000 RPS
This number, not user count, is the real architectural constraint.
Data Access Frequency
80–90% of frontend requests should not hit the database.
At scale, your foundation must rely heavily on:
- CloudFront
- ElastiCache (Redis)
- DynamoDB with DAX
- Precomputation and event-driven pipelines
Consistency Expectations
Distributed systems that scale accept:
- eventual consistency in many domains
- strong consistency only where absolutely necessary
With these inputs defined, you can design with intention instead of reacting to load spikes.
2. The Core AWS Architecture for 10 Million Users
A battle-tested high-scale architecture looks like this:
Client → CloudFront → API Gateway / ALB → ECS/EKS → DynamoDB + Aurora → Redis → SQS/SNS → Event-Driven Workers
Its principles:
- stateless compute
- distributed storage
- aggressive caching
- async by default
- autoscale everything
Let’s break it down.
3. Compute Layer: ECS Fargate or EKS for Infinite Horizontal Scaling
Running EC2 fleets becomes operationally heavy at this scale.
Option A: ECS Fargate, the default high-scale choice
Advantages:
- No servers or clusters to manage
- Per-task autoscaling
- Fast deploy, zero maintenance
- Seamless with ALB
- Ideal for microservices
Fargate can scale thousands of tasks in parallel when configured properly.
Option B: EKS, when you need full Kubernetes control
Choose EKS for:
- custom scheduling
- multi-cloud portability
- GPU workloads (ML/AI)
- dense service meshes
EKS is powerful but requires a stronger SRE/Platform team.
4. API Layer: API Gateway or ALB for Millions of Requests
Both are viable at scale, but with different strengths.
Use API Gateway when:
- you want a fully managed API tier
- request-level caching matters
- you rely on Lambda-heavy architectures
API Gateway supports tens of thousands of RPS out of the box.
Use ALB when:
- traffic is high, constant, and containerized
- you need very low latency
- your compute layer is on ECS/EKS
For 10M users, ALB + ECS Fargate is the most proven combo.
5. Data Layer: DynamoDB + Aurora = High Throughput + Strong Consistency
DynamoDB for high-volume operations
It handles:
- millions of RPS
- global replication
- microsecond reads with DAX
- zero-downtime scaling
Use DynamoDB for:
- user sessions
- access tokens
- activity logs
- high-frequency writes
- real-time counters
Aurora for relational consistency
Use Aurora Serverless v2 or provisioned clusters when you need:
- transactions
- financial workflows
- complex relational queries
- guaranteed consistency
The Hybrid Model
This is how the best AWS systems work:
Use DynamoDB for scale, Aurora for correctness.
6. Caching: Your Most Important Lever for Scaling to 10M Users
A system that can handle 20,000 RPS without caching will collapse at ~2,000 RPS.
AWS gives you three critical caching layers:
1. CloudFront (CDN)
Cache:
- static assets
- public API responses
- signed URLs
- dynamic personalized content with caching keys
CloudFront offloads massive traffic.
2. ElastiCache (Redis)
Your real-time, in-memory backbone.
Use it for:
- sessions
- rate limits
- leaderboards
- duplicate request suppression
- precomputed responses
- expensive DB query caching
3. Application-level caching
Cache business logic:
- decoded JWT keys
- ML inference results
- consolidated domain objects
Well-designed caching reduces backend load by 70–90%.
7. Asynchronous Processing: The Secret Weapon of High-Scale Systems
Every system at this scale depends on async workflows.
Use:
- SQS (durable queues)
- SNS (pub/sub)
- EventBridge (serverless event routing)
- Lambda or Fargate workers
Process asynchronously:
- notifications
- payment workflows
- ML predictions
- webhooks
- batch jobs
- data enrichment
Async workloads ensure synchronous requests stay fast regardless of load spikes.
8. Observability: You Cannot Scale What You Cannot See
At AWS scale, observability isn’t optional.
Use:
- CloudWatch Logs + Metrics
- X-Ray tracing
- CloudTrail
- OpenTelemetry (EKS)
Critical metrics:
- RPS per endpoint
- P99 latency
- DynamoDB throttles
- Redis memory pressure
- SQS queue depth
- autoscaling events
- connection saturation
Scaling must be predictable, not reactive.
9. Cost Optimization: Scaling and Saving Simultaneously
High-scale doesn’t have to mean high-cost.
Optimize with:
- DynamoDB auto-scaling
- Aurora Serverless v2
- Compute Savings Plans
- S3 Intelligent-Tiering
- aggressive caching (cheapest way to scale)
- running batch workloads on Spot EC2 or Spot Fargate
Efficient architecture beats expensive architecture every time.
10. Common Mistakes That Prevent Scaling
We see the same anti-patterns often:
- Using a relational DB for everything
- Running monolithic EC2 servers
- Not caching aggressively
- Overusing Lambda for synchronous high-volume loads
- Not load-testing before launch
- Ignoring async patterns
10M-user systems require deliberate engineering.
Final Recommendations for CTOs and Engineering Teams
To scale to 10 million users on AWS:
- Design clear service boundaries
- Use DynamoDB for high-frequency workloads
- Use Aurora for mission-critical transactions
- Deploy on ECS Fargate or EKS for unlimited horizontal scaling
- Treat caching as a first-class citizen
- Monitor everything
- Assume failure, design for spikes
Scaling is not an accident, it’s an architecture.
At JMS Technologies Inc., we help enterprises design, build, and operate AWS platforms that scale to tens of millions of users with predictable performance and cost efficiency.
Need a high-scale AWS architecture? Let’s talk.