How Kafka Works: Inside the Architecture of a Distributed Streaming Platform

- Published on
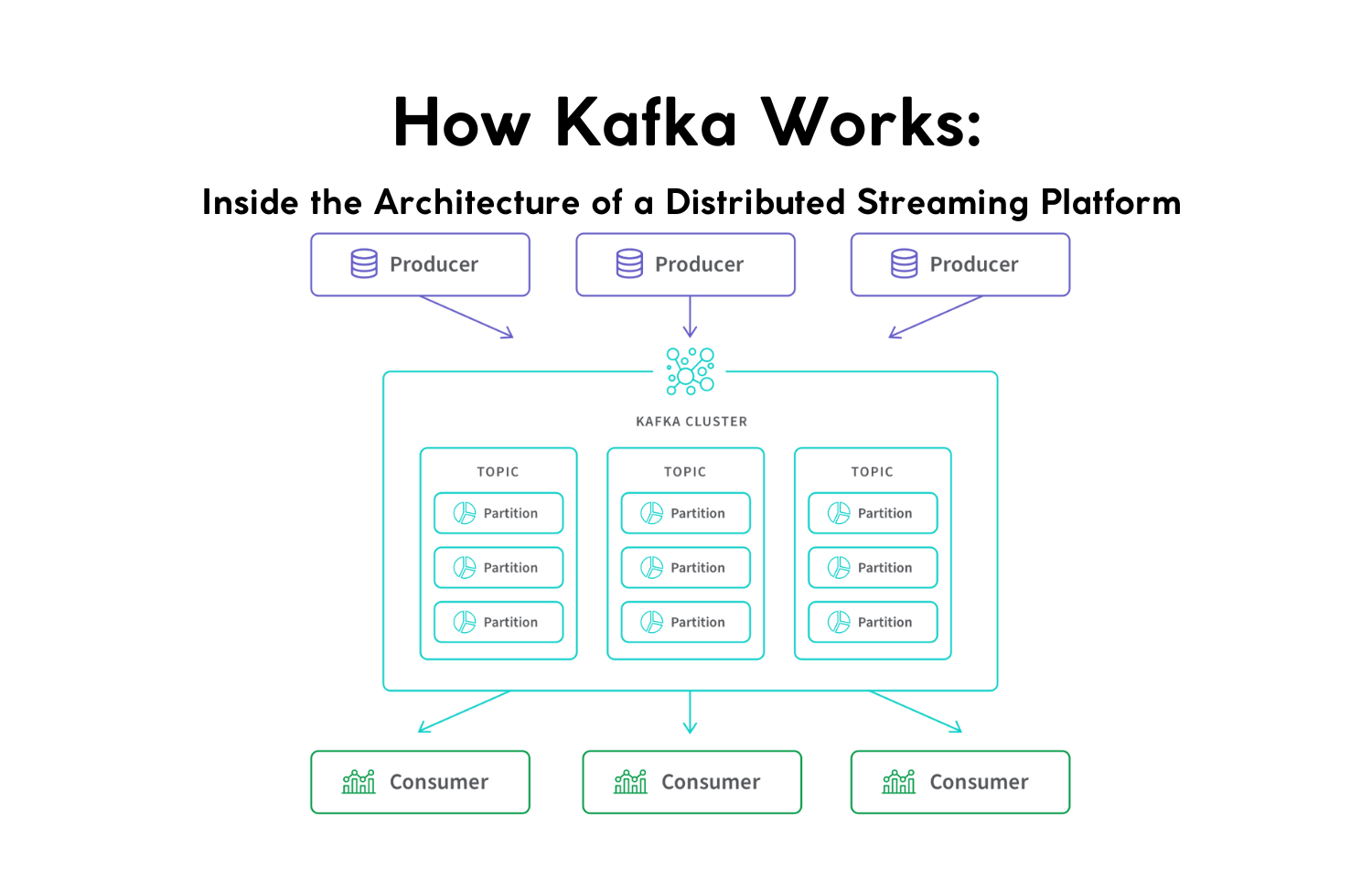
Understanding how Apache Kafka works internally is essential for any engineering leader building scalable event-driven systems. Kafka isn’t just a message broker, it’s a high-throughput distributed log system that powers real-time data pipelines, fintech architectures, IoT platforms, and mission-critical streaming workloads.
Kafka has become the backbone of companies that require millisecond latency, horizontal scalability, and fault-tolerant data movement across distributed systems.
For CTOs, staff engineers, and system architects, diving deep into Kafka reveals foundational principles of log-based storage, distributed consensus, backpressure control, partitioned dataflows, and stream processing at scale.
1. Why Kafka’s Architecture Matters in Modern Distributed Systems
Kafka’s adoption is accelerating across industries because it solves a fundamental problem:
How do we reliably capture, store, and distribute massive amounts of real-time data with consistency and low latency?
Modern platforms, payments, logistics, AI pipelines, user activity tracking, generate millions of events per second. Kafka provides:
- Durable event storage
- High-throughput sequential writes
- Partition-level parallelism
- Real-time consumer processing
- Guaranteed ordering per partition
- Seamless horizontal scaling
It isn’t designed like traditional brokers (RabbitMQ/ActiveMQ). Kafka’s architecture is fundamentally different:
It’s a distributed commit log system, optimized for sequential writes and efficient replication.
2. Log-Based Storage: The Core of Kafka’s Speed and Durability
At its heart, Kafka is a system of append-only sequential logs.
Kafka never rewrites existing data. Instead, each event is appended:
- Sequential disk writes → near SSD speeds
- OS page cache → extremely fast reads
- Immutable log → simplified replication
- High compression ratios → cost efficiency
Each partition’s log is divided into segments (commonly 1 GB). Once full, Kafka rolls over to a new one.
Why is this powerful?
Sequential I/O + page caching =
hundreds of thousands of messages per second with minimal CPU overhead.
This design allows Kafka to scale with predictable performance even under extreme throughput.
3. Topics, Partitions, and Segments: Kafka’s Horizontal Scaling Model
A Kafka topic is a logical stream, but the real work happens in partitions.
orders (topic)
├── partition 0 (log)
├── partition 1 (log)
└── partition 2 (log)
Why partitions?
- Enable true horizontal scaling
- Distribute load across brokers
- Allow parallel reads/writes
- Preserve ordering within each partition
Each partition is an independent log, replicated for durability and split into append-only segments.
This is what allows Kafka to scale into multi-region clusters processing billions of events per day.
4. Producers: How Kafka Handles Ingestion at Massive Scale
Kafka producers control how messages are routed, batched, compressed, and delivered.
Partitioning Strategies
Producers choose partitions via:
- Round-robin – even load distribution
- Key-based hashing – preserves ordering per key (common in payments, users)
- Custom logic – for advanced routing
Batching & Compression
Kafka producers batch messages and apply compression (LZ4/Snappy/Gzip):
- Dramatically reduces network overhead
- Improves throughput
- Lowers CPU load on brokers
Durability (acks)
acks=0→ fastest but unsafeacks=1→ leader-only durabilityacks=all→ leader + ISR replicas (recommended for fintech/logistics)
Producer logic is a huge lever for throughput optimization.
5. Brokers, Clusters, and Replication: Kafka’s Reliability Engine
A broker stores partitions and serves producer/consumer requests. Multiple brokers form a cluster.
Partition Leadership
Each partition has:
- 1 Leader → handles all reads/writes
- N Followers → replicate data
ISR (In-Sync Replicas)
Followers fully caught up with the leader are part of ISR.
If the leader fails:
A follower in ISR is promoted instantly to leader.
This guarantees high availability with minimal downtime.
Metadata Management
Kafka 2.8+ uses KRaft, removing the need for ZooKeeper and simplifying cluster operations.
6. Consumers & Consumer Groups: Parallelizing the Read Path
Consumers pull data at their own pace.
Consumer Groups
Kafka’s model guarantees:
- Each partition → consumed by exactly 1 consumer in the group
- Adding consumers → increases parallelism
- Failover → automatic redistribution (rebalance)
This enables:
- ML pipelines
- Distributed ETL
- Real-time microservices
- Streaming analytics
Offsets are stored in __consumer_offsets, allowing replay and exactly-once semantics in many workflows.
7. Offsets, Retention & Replay: Kafka as a Time-Travel System
Kafka does not delete messages when consumed.
Instead, it uses retention policies:
- Time-based (
retention.ms) - Size-based (
retention.bytes)
Offsets allow consumers to:
- Rewind (replay data)
- Resume processing after failures
- Skip to the latest records
Retention transforms Kafka into:
- A real-time buffer
- An event store
- An audit log
- A replay engine for ML
8. Kafka Connect & Kafka Streams: The Ecosystem That Powers Real-Time Dataflows
Kafka Connect
Connector-based integrations:
- Databases → Kafka (Debezium CDC)
- Kafka → BigQuery / Snowflake / Elasticsearch
- Kafka → Cloud storage (S3/GCS)
Zero custom code for most pipelines.
Kafka Streams
A lightweight processing framework offering:
- Windowing
- Joins
- Aggregations
- Exactly-once semantics
Runs inside microservices without external clusters.
9. Real-World Architectures & Use Cases
1. FinTech Payments
- Transaction events
- Fraud detection pipelines
- Audit logs
- Real-time notifications
Guaranteed ordering per user → consistency for ledgers.
2. On-Demand Logistics
- GPS tracking
- ETA calculation
- Dynamic pricing
- Cross-region ingestion
Millions of events/min with strict latency budgets.
3. IoT & Sensor Networks
- Massive ingestion
- Edge processing
- Temporal joins
- Cloud analytics
Kafka handles backpressure and burst traffic effortlessly.
10. Common Mistakes & Best Practices
Mistakes
- Too few partitions
- Misconfigured
min.insync.replicas - Auto-commit offsets → inconsistent processing
- Not using keys → ordering issues
- Treating Kafka like OLTP
Best Practices
- Partition based on throughput needs
- Use compression (producer + broker)
- Monitor consumer lag & ISR size
- Dedicate brokers for critical topics
- Separate streaming vs transactional workloads
What CTOs & Engineering Leaders Can Learn
Kafka demonstrates several universal distributed systems principles:
- Sequential I/O is king for throughput and durability.
- Partitioning is the path to scale, design around it.
- Replication must be fast and predictable to keep SLAs.
- Stream processing works best when the log is the source of truth.
- Backpressure and replayability are essential for robust architectures.
Kafka’s architecture is a masterclass in simplicity + power: a distributed commit log that scales to billions of events per day.
Conclusion
Kafka has earned its place as the standard for event streaming by combining:
- Sequential log-based storage
- Horizontal scaling via partitions
- High-throughput producers
- Fault-tolerant replication
- Flexible retention & replay
- A rich ecosystem for real-time processing
At JMS Technologies Inc., we design and build large-scale event-driven systems using these Kafka principles to deliver resilient, high-performance distributed architectures.
Need to design a large-scale streaming system? Let’s talk.