Microservices vs AI-Native Architecture: Two Paradigms, One Platform

- Published on
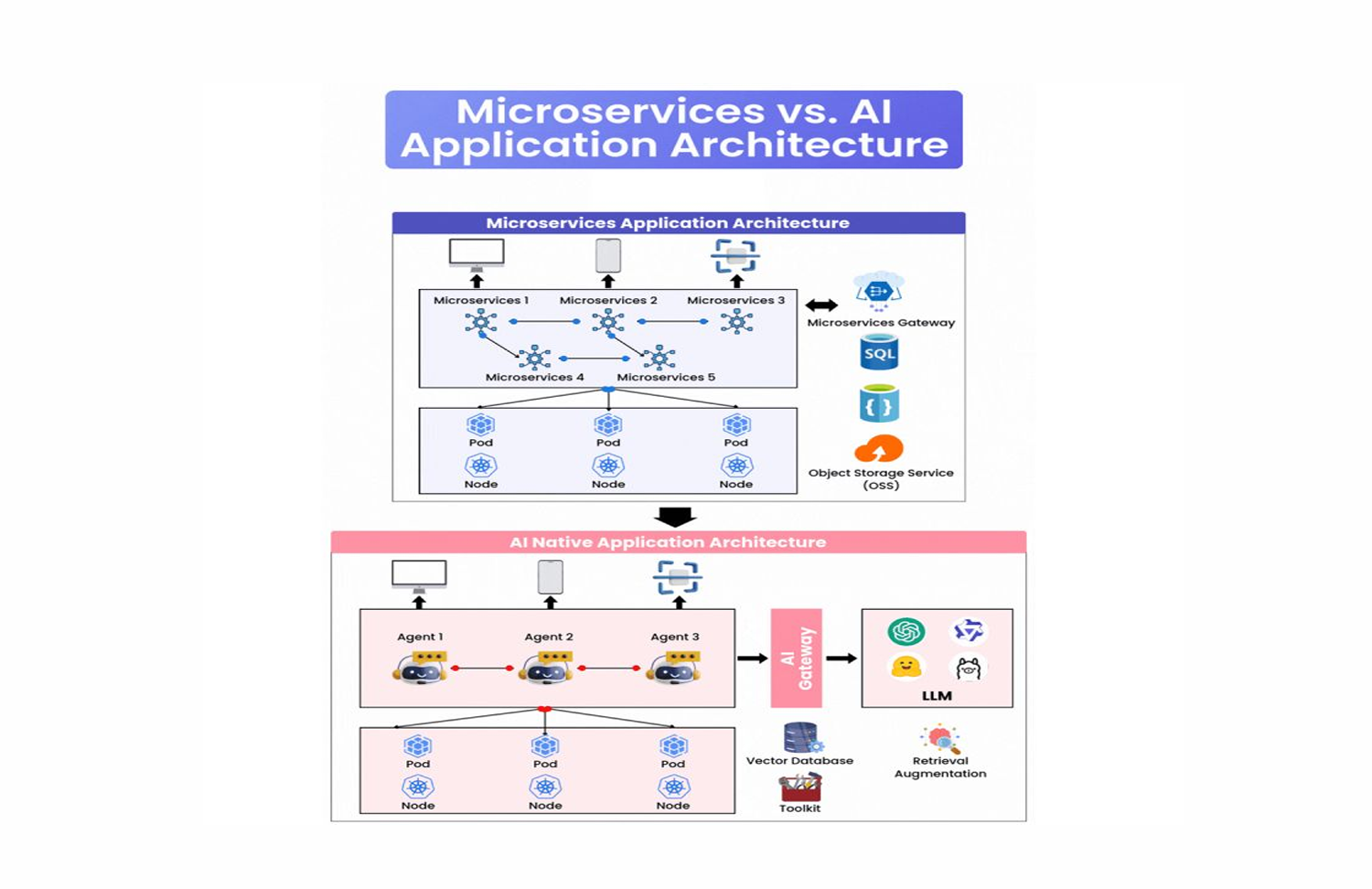
For the past decade, microservices have been the dominant paradigm for building large-scale applications. Independent services, lightweight APIs, bounded ownership, horizontal scalability. The model proved itself across hundreds of production systems handling billions of requests.
AI-native architecture is now emerging as a distinct paradigm alongside it. Not as a replacement, but as a fundamentally different approach to a fundamentally different kind of problem.
Understanding both paradigms at the structural level, and knowing when to apply each, is the core competency of platform engineers working in 2024 and beyond.
1. What Each Paradigm Is Actually Optimizing For
This is the question that clarifies everything else.
Microservices optimize for business logic execution. The central challenge they solve is: how do you build a large, complex application so that many teams can work on it independently, deploy changes without coordination overhead, and scale individual components based on load? The answer is decomposition by business capability: order service, user service, payment service, notification service. Each owns its domain, exposes an API, and handles its own data.
AI-native architectures optimize for intelligence. The central challenge they solve is different: how do you build a system that can reason over context, retrieve relevant knowledge, plan multi-step actions, and produce outputs that require understanding rather than just execution? The answer involves a different set of primitives: language models, vector databases, retrieval pipelines, and agent frameworks.
These are not competing answers to the same question. They are answers to different questions. The confusion in most architectural discussions comes from treating them as alternatives when they are better understood as complementary layers.
2. Microservices Architecture: The Structure in Depth
A microservices architecture has a well-established set of components, each with a specific role.
API Gateway
The API Gateway is the single entry point to the system. Every external request passes through it before reaching any service. Its responsibilities are:
- Authentication and authorization: verify identity and enforce access control before requests reach business logic
- Rate limiting and load balancing: protect downstream services from traffic spikes and distribute load across instances
- Routing: direct requests to the appropriate service based on path, headers, or other routing rules
- Fault tolerance: implement circuit breakers, retries, and timeouts at the boundary layer
The Gateway's value is centralization of cross-cutting concerns. Without it, every service implements its own auth, its own rate limiting, its own retry logic. That duplication is expensive to maintain and inconsistent in behavior.
Independent Services
Each service owns a specific business capability and a clear bounded context. The boundaries should align with domain concepts, not technical layers. An order service handles everything related to orders. A payment service handles everything related to payments. They communicate via well-defined APIs, typically REST or gRPC, and they do not share databases.
The independence is what produces the organizational benefits: teams can deploy their service without coordinating with other teams, scale it independently based on its specific load profile, and choose its technology stack based on the requirements of its domain.
Storage Backends
Microservices patterns favor polyglot persistence: each service uses the storage technology best suited to its access patterns.
- SQL databases for structured, transactional data with strong consistency requirements: financial records, user accounts, inventory
- Object storage for unstructured data: images, videos, documents, large files that do not need to be queried relationally
The key principle is that storage is owned by the service. No other service queries a service's database directly. All access goes through the service's API.
Kubernetes as the Runtime Foundation
Kubernetes provides the infrastructure layer that makes microservices operationally viable at scale.
- Pods are the smallest deployable unit: one or more containers that share networking and storage, deployed together
- Nodes are the machines that run pods: either physical servers or virtual machines in a cloud environment
Kubernetes handles scheduling, scaling, health checking, and rolling deployments. It abstracts the infrastructure so that services declare what they need (CPU, memory, replica count) and Kubernetes figures out how to fulfill those requirements across the cluster.
3. AI-Native Architecture: The Structure in Depth
AI-native architecture shares some components with microservices (Kubernetes, APIs, storage) but introduces a distinct set of primitives organized around a different execution model.
AI Gateway
The AI Gateway plays a similar boundary role to the API Gateway in microservices, but its concerns are specific to AI workloads:
- Model routing: direct requests to the appropriate model based on capability requirements, cost constraints, or latency targets. A simple classification task routes to a smaller, faster model. A complex reasoning task routes to a larger, more capable model.
- Multi-step workflow orchestration: coordinate sequences of LLM calls, retrieval operations, and tool invocations that together produce a final output
- Cost management: track token usage per request, enforce budget limits, and apply caching policies to reduce redundant inference calls
- Observability: capture prompt/response pairs, latency, token counts, and quality signals for monitoring and evaluation
The AI Gateway is the component that makes AI workloads operationally manageable at production scale. Without it, cost visibility, model routing, and workflow coordination are handled ad hoc in application code, which does not scale.
LLM: The Reasoning Engine
The Large Language Model is the core of an AI-native system. Its role is categorically different from a traditional service: it does not execute deterministic logic, it reasons over context.
Given a prompt containing instructions, retrieved context, and user input, the LLM generates a response. That response might be a direct answer, a structured output parsed by the system, a plan of action for an agent to execute, or a decision about which tool to invoke.
The LLM is stateless at the call level. Context is assembled by the application layer and passed in the prompt. The quality of the output is directly dependent on the quality of the context provided, which is why retrieval architecture is as important as model selection.
Vector Database
The vector database is purpose-built for one operation: given a query, find the stored items most semantically similar to it.
Traditional databases answer exact or range queries: give me all orders with status "pending", or all users created after a given date. Vector databases answer semantic queries: give me the documents most relevant to this question, the products most similar to this description, the support tickets most similar to this new issue.
They do this by storing data as high-dimensional vectors (embeddings), where the position of a vector in the space encodes semantic meaning. The distance between vectors corresponds to semantic similarity. Approximate nearest-neighbor search algorithms find the closest matches at low latency even across billions of stored embeddings.
In an AI-native system, the vector database is the memory layer. It stores knowledge that the LLM needs to retrieve at inference time.
Retrieval Augmented Generation (RAG)
RAG is the pattern that connects the vector database to the LLM in a way that produces reliable, grounded outputs.
The problem RAG solves is fundamental: LLMs have a knowledge cutoff, a limited context window, and no access to your proprietary data. Without retrieval, the model can only reason about what it learned during training, which is both outdated and generic.
With RAG, the system:
- Converts the user query into an embedding
- Searches the vector database for the most semantically relevant documents
- Injects those documents into the LLM prompt as context
- Generates a response grounded in the retrieved content
The result is a model that can answer questions about your current data, your internal documentation, your product catalog, or any other corpus you have indexed, without fine-tuning the model itself.
Retrieval quality is the primary lever for output quality in RAG-based systems. A well-designed retrieval pipeline with hybrid search (dense vector retrieval combined with sparse keyword matching), re-ranking, and domain-specific embeddings will outperform a larger model given poor retrieval.
Agents and Tool Use
AI agents extend the LLM from a question-answering system to an action-taking system. An agent can invoke external tools: run a database query, call an API, execute code, write a file, or trigger a workflow in another system.
The agent loop is:
- Receive a goal or task from the user
- Reason about what steps are required to complete it
- Select and invoke the appropriate tool
- Observe the result
- Reason about the next step
- Repeat until the goal is complete or the agent determines it cannot proceed
This is a fundamentally different interaction pattern from a traditional service. The execution path is not deterministic. The model decides, at runtime, which steps to take. This produces flexibility that is impossible in hard-coded logic, and introduces failure modes that require different observability and safety approaches.
4. Where the Two Architectures Intersect
In production systems, microservices and AI-native architecture are not separate systems. They are layers that interact.
The most common pattern is AI capabilities embedded within a microservices platform:
- An AI gateway routes requests to models and orchestrates agent workflows, sitting alongside the API gateway in the request path
- AI services (retrieval service, embedding service, agent orchestration service) are microservices themselves, owned by specific teams, with their own APIs and SLOs
- The vector database is a storage backend like any other: accessed through a service interface, not directly by application code
- Kubernetes runs AI workloads alongside traditional workloads: GPU node pools for inference, standard CPU pools for business logic services
The integration point requires careful design. AI services have different performance characteristics than traditional services: higher latency variance, token-based cost models, and probabilistic rather than deterministic outputs. These properties require AI-specific observability and evaluation systems sitting alongside standard infrastructure monitoring.
5. Common Architectural Mistakes
Treating the LLM as a service endpoint. Calling an LLM API from application code without a retrieval layer, cost controls, or an AI gateway is not AI-native architecture. It is an API call. The infrastructure that makes AI reliable and economically sustainable in production is distinct from the model access itself.
Under-investing in retrieval. Most teams spend disproportionate time on model selection and prompt engineering relative to retrieval architecture. In production RAG systems, retrieval quality is the dominant factor in output quality. Embedding strategy, index freshness, hybrid search, and re-ranking deserve serious engineering investment.
Ignoring cost architecture. LLM inference is priced per token. At production scale, token costs are infrastructure costs. Teams that do not build cost governance into the architecture from the start discover this expensively when their first invoice arrives.
Skipping evaluation infrastructure. Traditional software has tests. AI systems have evaluations. Building production AI without an evaluation pipeline, a golden dataset, and continuous quality monitoring is equivalent to deploying traditional software without unit tests. The failure modes are different but the absence of systematic quality assurance is equally dangerous.
Premature agent autonomy. Agents that take actions in production systems require careful human-in-the-loop design, audit logging, and rollback capabilities. Deploying autonomous agents without these controls is an operational risk that few teams fully appreciate until something goes wrong.
6. Choosing the Right Architecture for the Right Problem
The decision framework is relatively clear once you understand what each paradigm optimizes for.
Use microservices when:
- The primary complexity is business logic that benefits from domain decomposition
- Multiple teams need to work and deploy independently
- Scale requirements vary significantly across different system components
- Strong consistency, transactional integrity, or regulatory compliance are requirements
Use AI-native patterns when:
- The system needs to reason over unstructured content or complex context
- Outputs require understanding rather than deterministic rule execution
- The value proposition depends on semantic search, personalization, or natural language interaction
- You are building agent workflows that plan and take multi-step actions
Combine both when:
- Your platform serves traditional business logic and AI-powered capabilities together
- AI features need to read from and write to the same data that powers your core services
- You need the operational maturity of microservices (deployment independence, team ownership, SLOs) applied to AI workloads
Most production platforms at meaningful scale fall into the third category. The engineering challenge is not choosing between the paradigms but integrating them cleanly, with clear ownership boundaries, consistent observability, and a cost model that works at scale.
Conclusion
Microservices and AI-native architecture are both mature answers to distinct problems.
Microservices decompose business complexity into independently owned, independently deployable services. They have been proven at scale across thousands of production systems. Their failure modes are well-understood and their operational tooling is mature.
AI-native architectures bring reasoning, retrieval, and autonomous execution to applications that need to understand context and act on it. They are earlier in their maturity cycle but advancing rapidly, and the teams building them now are developing the operational knowledge that will define best practices for the next decade.
The real advantage does not come from committing entirely to one or the other. It comes from understanding both clearly enough to combine them deliberately: using microservices for what microservices do well and AI-native patterns for what AI-native patterns do well, with the integration layer designed to maintain the properties both paradigms depend on.
At JMS Technologies Inc., we design platforms that operate at both levels, building the distributed systems foundations that make AI capabilities reliable, observable, and economically sustainable in production.
Designing a platform that needs both paradigms? Let's talk.