The Era of Generalist AI Is Over. Here Are the 8 Architectures Defining the Modern Stack.

- Published on
Most teams are still building AI products as if LLMs are the only architecture that exists.
That assumption is now a liability.
In production, a single massive model is not a strategy. It is technical debt with a GPU bill attached. The latency is too high for real-time UX. The cost is too high for anything at scale. The hallucination rate is too high for domains where precision is non-negotiable. And the blast radius when it fails is the entire product, because nothing else in the system can absorb the load.
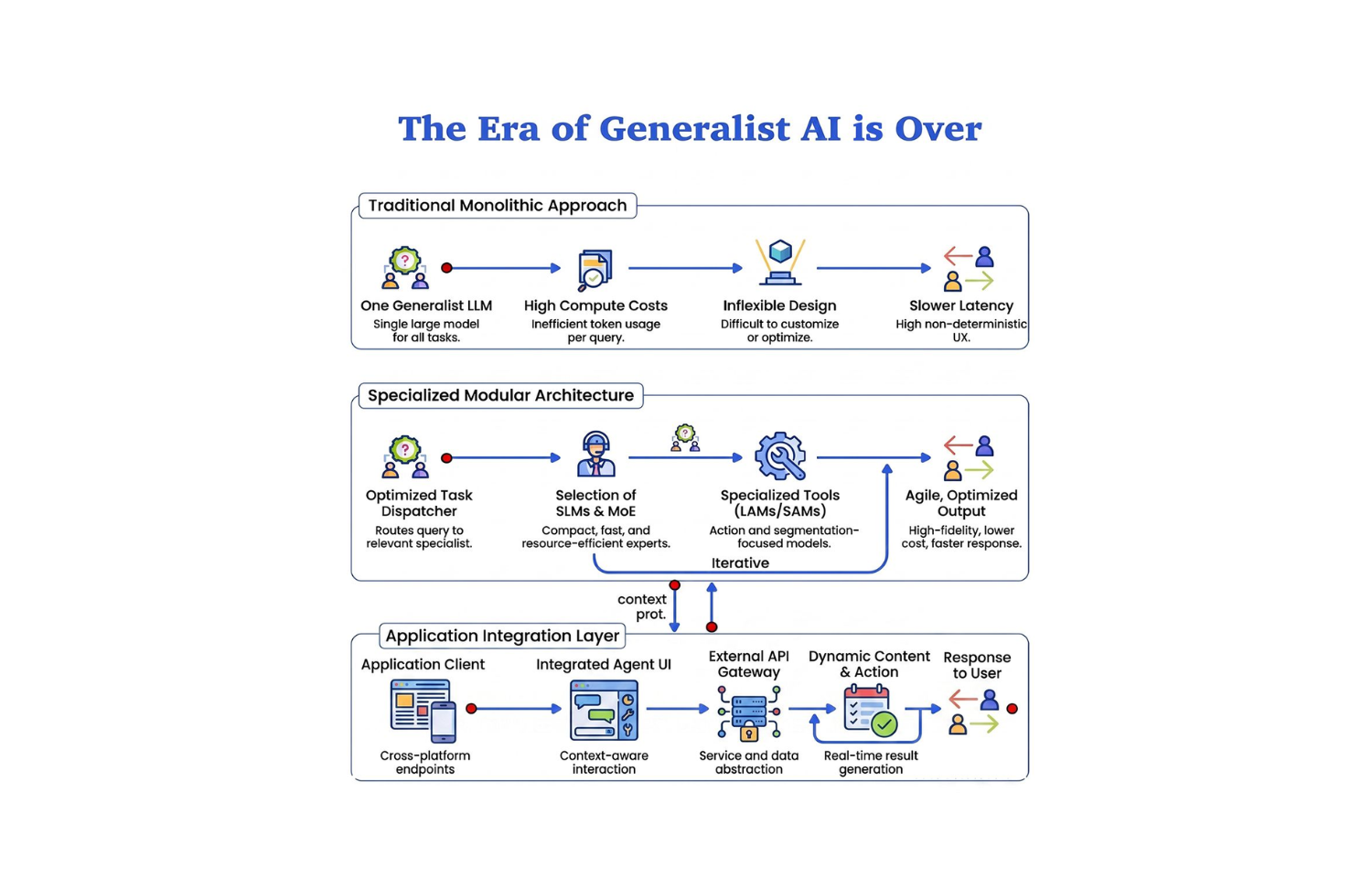
The teams pulling ahead are not using more AI. They are designing better architectures.
The real shift is from monolithic AI to modular AI systems. And understanding the eight architectures driving that shift is the difference between teams that ship reliable products at scale and teams that keep hitting the same wall with the same tool.
Why Generalist AI Became a Liability
The premise of the early LLM era was compelling: one model that can do everything. Write code, answer questions, summarize documents, generate images, reason about data, draft emails, all from a single API endpoint.
That premise worked at demo scale. It breaks at production scale.
The economics do not hold. You are paying frontier model inference costs for tasks that do not require frontier model capability. Classifying an incoming support ticket does not need GPT-4-level reasoning. Extracting structured data from a receipt does not need a 100-billion-parameter model. Running a masked language model or a fine-tuned SLM on those tasks cuts cost by an order of magnitude with equivalent or better accuracy.
The latency does not hold either. Frontier model inference takes time. For anything surfaced to a user, search, recommendations, real-time classification, mobile applications, the latency profile of a large general model is often disqualifying. Specialized smaller models return results in milliseconds that a large model returns in seconds.
And reliability does not hold. General models hallucinate because they are trained to generate plausible text, not to be correct. Narrower architectures, deterministic retrieval, structured classification, task-specific fine-tuning, reduce hallucination rates by narrowing the output space. The model cannot hallucinate something outside its task definition.
The question is not "can we solve this with an LLM?" The question is "what is the right architecture for this problem?"
The 8 Architectures Defining the Modern Stack
1. LLMs: Large Language Models
The reasoning layer. Still the most capable architecture for synthesis, complex multi-step logic, open-ended generation, and tasks where the output space cannot be predefined.
LLMs are expensive and often overused. The right position for an LLM in a production system is the final reasoning step after cheaper architectures have done the retrieval, filtering, and classification work. Not the first call in the pipeline. Not the default answer to every integration question.
When LLMs are the right choice: complex reasoning, synthesis across multiple sources, open-ended generation, tasks where domain breadth matters more than latency or cost.
When they are not: classification, extraction, embedding, retrieval, anything with a well-defined output space, anything on-device or latency-critical.
# Anti-pattern: LLM for everything
result = llm.complete("Classify this support ticket: " + ticket_text)
# Better: Use the right architecture per step
category = classifier.predict(ticket_text) # SLM or MLM, fast, cheap
embedding = encoder.embed(ticket_text) # MLM, retrieval
context = retriever.search(embedding, top_k=5) # Deterministic
response = llm.complete(ticket_text, context) # LLM only for final synthesis
2. LCMs: Large Concept Models
Meta's architectural shift from token prediction to concept-level understanding. LCMs operate in the space of meaning, not vocabulary. Where LLMs predict the next token in a sequence, LCMs reason about the next concept in a semantic graph.
This is early-stage technology, but the implications are significant. Token-level models have a hard ceiling on genuine semantic understanding because the training objective optimizes for surface-level pattern matching. Concept-level models have a different training objective that more directly targets semantic coherence.
Watch this space for tasks where LLMs consistently fail on genuinely novel reasoning: analogical thinking across domains, semantic consistency over very long documents, and compositional concept manipulation.
3. VLMs: Vision-Language Models
VLMs connect visual input with semantic meaning. They bridge the modality gap that pure language models cannot cross: a floor plan, a skin lesion, a manufacturing defect, a damaged vehicle panel. These are not describable in text with sufficient fidelity for downstream decisions. VLMs process the image directly.
The production applications are maturing rapidly. Real estate platforms use VLMs to assess property condition from listing photos and flag discrepancies in staging. E-commerce systems use them for visual search, product matching, and automated attribute extraction from product images. Healthcare applications use them for triage support, pattern recognition, and report-to-image consistency checks. Manufacturing inspection systems use them to catch defects that visual QC pipelines miss.
# VLM for structured extraction from visual input
result = vlm.analyze(
image=product_image,
prompt="Extract: brand, condition (1-10), visible defects, estimated category"
)
# Returns structured data from unstructured visual input
# No manual labeling pipeline, no human QC bottleneck
If your product involves images and decisions that depend on those images, a VLM is the right architectural component. An LLM with an image description is not equivalent.
4. SLMs: Small Language Models
SLMs are the most underutilized architecture in most production stacks.
Small Language Models run fast, run cheap, and run anywhere. Latency in single-digit milliseconds on commodity hardware. Deployable on mobile devices, edge nodes, and IoT endpoints. Cost that scales to billions of inferences without requiring a dedicated infrastructure budget line.
The capability trade-off is real, SLMs cannot match frontier LLMs on complex reasoning. But for the majority of production AI tasks, complex reasoning is not what is required. Sentiment analysis. Intent classification. Named entity extraction. Language detection. Safety filtering. Short-form generation within a defined template. These tasks do not require a 100-billion-parameter model. They require a fast, reliable, task-specific model that runs at scale.
The architecture pattern that works: fine-tune an SLM on your specific task distribution, deploy it as the first-pass layer, and escalate only to a frontier model when the SLM's confidence score falls below threshold. The escalation rate on most production tasks is 10–20%. You pay frontier model costs on 10–20% of requests instead of 100%.
5. MoE: Mixture of Experts
Mixture of Experts solves the fundamental economics problem of large model architecture: you cannot make a model better without making it bigger, and making it bigger makes every inference more expensive.
MoE breaks that relationship. Instead of activating the full parameter set for every token, MoE trains specialized sub-networks (experts) and a routing layer that selects which experts to activate for a given input. A 100-billion-parameter MoE model might activate 10–15 billion parameters per inference, matching the quality of a dense model at a fraction of the compute cost.
GPT-4, Gemini 1.5, Mixtral, and Grok all use MoE architecture. The quality-per-FLOP improvements are not marginal. They are the reason frontier model capability keeps improving without proportional cost increases.
For teams building custom models or selecting hosted models: prefer MoE architectures when you need frontier-adjacent quality at scale. The cost profile makes deployment sustainable at volumes where dense models would be prohibitive.
Dense Model: All 100B parameters activated per token
MoE Model: 8 of 64 experts activated per token
≈ 12B effective parameters per inference
≈ 6x cost reduction, comparable quality
6. MLMs: Masked Language Models
Masked Language Models are the workhorse of production NLP that most AI product teams have stopped talking about, and are still running in their most critical systems.
BERT, RoBERTa, DeBERTa, and their descendants are not obsolete. They are the backbone of search ranking, content classification, semantic similarity, and retrieval augmentation in production systems at every major tech company. They produce dense semantic embeddings in milliseconds. They run at a cost that makes embedding billions of documents feasible. They power the retrieval layer that every RAG system depends on.
The MLM's natural position in the modern stack is the embedding and retrieval layer. You embed documents with an MLM once. You query with it at inference time. An LLM reasons over the retrieved context. This is not a workaround, it is the correct architecture for knowledge-heavy systems where accuracy and retrieval precision matter.
If you are using an LLM to do semantic search by generating answers and hoping they match, you are using the wrong architecture for retrieval.
7. LAMs: Large Action Models
Large Action Models are the bridge from AI that thinks to AI that does.
Where LLMs generate text about what should happen, LAMs generate and execute sequences of actions, API calls, browser interactions, form submissions, workflow orchestration, code execution. The training objective is not to produce plausible text. It is to produce executable action sequences that achieve defined goals in real environments.
LAMs underpin the autonomous agent category. Computer use agents, workflow automation platforms, RPA successors, and agentic coding tools are all LAM applications. The architecture trains on interaction data, sequences of observations and actions, rather than just text corpora, which produces fundamentally different capability profiles for task completion.
The relevant production pattern: use an LLM to plan and reason about a complex task, then hand off the execution sequence to a LAM or LAM-like agent that can handle the action loop reliably without re-planning from scratch at each step.
Task: "Collect Q1 metrics from Salesforce, Stripe, and Mixpanel and generate the board report"
LLM Layer: Understand task → Plan steps → Identify data dependencies → Define output schema
LAM Layer: Execute plan → Auth to Salesforce API → Query CRM data → Auth to Stripe →
Pull transaction data → Auth to Mixpanel → Pull event data → Assemble report
(No re-planning. Execute the action graph. Handle errors. Retry on failure.)
This is the architecture behind every serious workflow automation product shipping in 2026.
8. SAMs: Segment Anything Models
Segment Anything Models give you pixel-level precision in visual understanding. Not "there is a person in this image", but exactly which pixels constitute that person, that car, that lesion, that crack in the pavement, that circuit board defect.
SAM's zero-shot segmentation capability, segmenting objects it was never explicitly trained on, removed the barrier that kept precise visual AI out of most production systems. Previously, getting reliable segmentation required domain-specific labeled datasets and expensive fine-tuning. SAM can segment novel objects with a prompt.
The applications that become viable with SAM: medical image analysis at scale, satellite and aerial imagery for urban planning and agricultural assessment, autonomous vehicle perception systems, AR/VR applications requiring precise object boundaries, quality inspection in manufacturing, and any spatial understanding task where bounding boxes are not sufficient.
If your product needs to answer "exactly where is this thing?" rather than "is this thing present?", SAM is the correct architecture. VLMs give you semantic understanding. SAMs give you spatial precision.
What Actually Moves the Needle
The bottleneck teams hit and the architecture that resolves it:
Cost is too high → The LLM is handling tasks that do not require frontier-level capability. Move classification, extraction, and retrieval to SLMs and MLMs. Escalate to LLMs only on low-confidence outputs. Target: 80% of volume handled by cheaper models, 20% escalated.
Latency is too high → Specialized and on-device models. Fine-tuned SLMs on edge hardware return results in under 10ms. MoE models at lower activation rates. Remove the LLM from the real-time response path wherever it is not strictly required.
Accuracy is not good enough → You have a general model doing a specialized task. Narrow the architecture. A fine-tuned SLM trained on 10,000 examples from your specific domain will outperform a general frontier model on that domain. Narrower systems have less hallucination surface. The output space is constrained.
Scaling is creating exponential cost → MoE at the model layer. Multi-tier routing at the system layer. Not every request should reach the same model. Build the routing logic that sends each request to the cheapest model capable of handling it at the required quality level.
The Architecture Decision Framework
Before writing any model integration code, map the task to five properties:
Task: _____________________
1. Output space: [ ] Open-ended [ ] Constrained [ ] Structured
2. Modality: [ ] Text only [ ] Image + Text [ ] Action
3. Latency budget: [ ] <50ms [ ] <500ms [ ] <5s
4. Volume: [ ] <10K/day [ ] <1M/day [ ] >1M/day
5. Precision req: [ ] Approximate [ ] High [ ] Pixel-level
Routing output:
- Open + Text + <5s + <10K/day + High → LLM
- Constrained + Text + <50ms + >1M/day → SLM or MLM
- Image + Text + High precision → VLM
- Action + Multi-step → LAM
- Image + Pixel precision → SAM
- Scale + Cost constraint → MoE
This is not a rigid decision tree. It is a forcing function to stop defaulting to LLMs and start thinking about fit.
The Production Architecture Pattern
The systems that work at scale are not single-model. They are pipelines where each layer uses the right architecture for its specific responsibility.
┌──────────────────────────────────────────────────────────┐
│ Input │
└───────────────────────┬──────────────────────────────────┘
│
┌─────────────▼─────────────┐
│ MLM, Embed + Route │ Fast semantic routing
└─────────────┬─────────────┘
│
┌───────────────┼───────────────┐
│ │ │
┌────▼────┐ ┌─────▼─────┐ ┌─────▼─────┐
│ SLM │ │ VLM │ │ SAM │
│Classify │ │ Understand│ │ Segment │
│Extract │ │ Image │ │ Locate │
└────┬────┘ └─────┬─────┘ └─────┬─────┘
│ │ │
└───────────────┼───────────────┘
│
┌─────────────▼─────────────┐
│ LLM/MoE, Reason + Synth │ Only what needs reasoning
└─────────────┬─────────────┘
│
┌─────────────▼─────────────┐
│ LAM, Execute + Act │ Only if action required
└───────────────────────────┘
Each layer does exactly what it is suited for. The LLM handles only the reasoning step at the end of the pipeline, not the retrieval, not the classification, not the embedding, not the execution. The result: lower cost, lower latency, fewer hallucinations, more reliable at scale.
Conclusion
The era of "one LLM to rule them all" was always a prototype era. It was the moment when AI became accessible enough to ship, before teams had enough production experience to learn where it breaks.
We are now past that moment.
AI is no longer about prompts. It is about system design. The teams winning are not the ones with access to the best model, access is a commodity now. The teams winning are the ones that understand which architecture fits which problem, and build systems that route intelligently across the stack.
Monolithic AI produces demo products. Modular AI produces production systems.
The question is no longer "can we solve this with an LLM?" The question is "what is the right architecture for this problem?", and then having the engineering capability to implement the answer.
At JMS Technologies Inc., we design production AI systems across the full model stack, from SLM-powered classification layers to multi-architecture pipelines that route intelligently across LLMs, VLMs, SLMs, and LAMs based on task shape, cost constraints, and quality requirements.
Hitting a wall with cost, latency, accuracy, or scale? Let's look at the architecture.