RAG vs Agentic RAG vs MCP: What's Really Powering the Next Generation of AI Integration

- Published on
Retrieval-Augmented Generation started as a research technique and became, in the span of a few years, the foundational pattern for production AI systems that need to reason over real data.
But RAG as it was originally implemented is a static pipeline. And static pipelines have a predictable ceiling: they work well on well-defined retrieval tasks and degrade reliably as complexity, ambiguity, and data diversity increase.
Two architectural evolutions have emerged to address this ceiling. Agentic RAG introduces reasoning into the retrieval loop. The Model Context Protocol, introduced by Anthropic, goes further: it standardizes how AI systems connect to the world beyond retrieval entirely.
Understanding all three clearly, their mechanics, their tradeoffs, and their relationship to each other, is the foundational knowledge for engineering AI systems that survive production at enterprise scale.
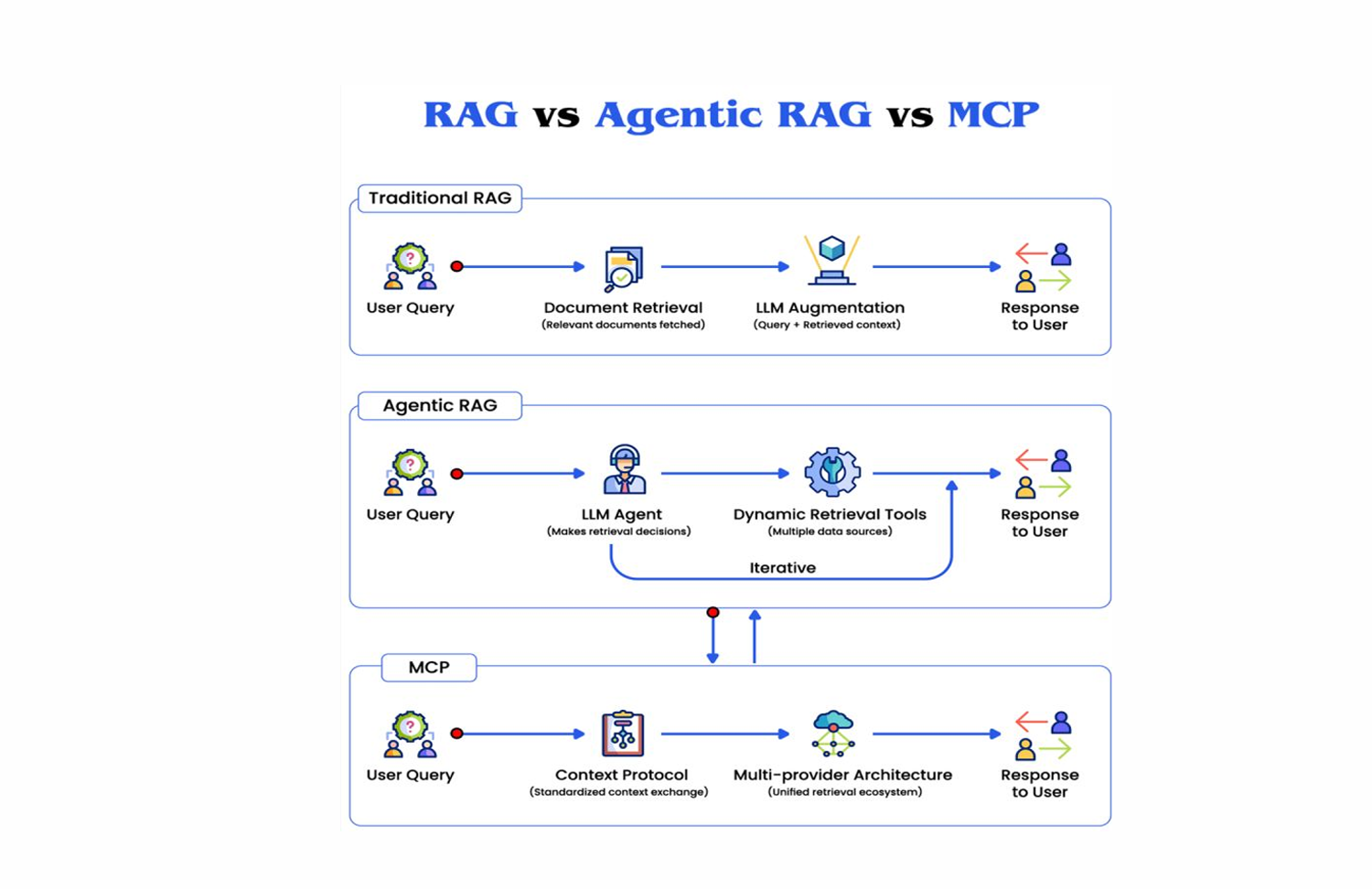
1. Traditional RAG: The Static Pipeline
To understand what Agentic RAG and MCP solve, you need to understand what traditional RAG does and where its limits are.
The traditional RAG pipeline is a linear sequence:
User Query
→ Embedding Model (query to vector)
→ Vector Database (approximate nearest-neighbor search)
→ Retrieved Documents (top-k chunks by semantic similarity)
→ LLM Prompt (query + retrieved context)
→ Generated Response
This pipeline works well under a specific set of conditions: the query is clear, the relevant information lives in a single indexed corpus, and a single retrieval pass surfaces the right context.
For a large fraction of real enterprise queries, none of these conditions hold.
Multi-hop questions require information from multiple sources that cannot be identified until the first retrieval reveals what is missing. "What are the revenue implications of the regulatory change announced last quarter?" requires retrieving the regulatory change, then retrieving the revenue model, then reasoning about the intersection. A single retrieval pass will not surface both unless the index was pre-built with that relationship in mind.
Ambiguous queries produce poor retrieval results because the embedding of an ambiguous query is itself ambiguous. The vector database returns what is semantically closest to the query as stated, not what the user actually needed. There is no mechanism for the system to ask a clarifying question or reformulate the query.
Multi-source retrieval is structurally awkward in traditional RAG. If the relevant context spans a document store, a SQL database, and an internal API, the pipeline needs to be explicitly engineered for each source combination. There is no general mechanism for routing a query to the right source type.
Context window management becomes a failure mode at scale. If the top-k retrieved chunks exceed the LLM's context window, or if the irrelevant chunks dilute the signal, output quality degrades without any visible signal to the user.
Traditional RAG is not wrong. It is appropriate for the scope of problems it was designed for. The problem is that enterprise AI requirements consistently exceed that scope.
2. Agentic RAG: Intelligence Enters the Retrieval Loop
Agentic RAG is not a modification of the traditional pipeline. It is a fundamentally different execution model.
In traditional RAG, the retrieval strategy is fixed at design time. The same pipeline runs for every query. The system has no mechanism for deciding that a particular query requires a different retrieval approach, multiple retrieval passes, or access to a different source.
In Agentic RAG, an AI agent governs the retrieval process. The agent:
- Analyzes the query to determine what information is needed and whether it is present in the available context
- Plans a retrieval strategy based on the query characteristics: which source to query, what search terms to use, whether multiple retrieval passes are needed
- Executes retrieval against one or more sources
- Evaluates the results to determine whether the retrieved context is sufficient to answer the query
- Iterates if the context is insufficient: reformulates the query, queries a different source, or flags that the information is unavailable
This execution model solves the structural limitations of traditional RAG at the cost of additional latency and complexity.
Multi-Step Reasoning with Retrieval
The agent can chain retrieval steps where each step is informed by the results of the previous one. For the regulatory revenue question above, the execution might look like:
Step 1: Retrieve regulatory announcements from Q3 2026
→ Retrieved: [Regulation X announced October 2026]
Step 2: Retrieve revenue impact models related to Regulation X
→ Retrieved: [Revenue model sections referencing compliance costs]
Step 3: Synthesize: what are the projected revenue implications?
→ Generated: [Response grounded in both retrieved contexts]
Neither step 2 nor step 3 could have been executed correctly without the output of the previous step. This is impossible in a single-pass static pipeline.
Query Reformulation and Validation
The agent can detect when retrieved context does not match the information need and reformulate. This addresses the ambiguous query problem directly. Instead of returning a low-confidence answer grounded in marginally relevant documents, the agent can attempt a different query formulation, query a different index, or indicate that the query cannot be answered confidently with available information.
Tool-Augmented Retrieval
Agentic RAG naturally extends to tool use. The agent does not only retrieve from a vector database. It can invoke:
- SQL queries against structured databases for precise relational lookups
- API calls to fetch live data (current inventory, real-time pricing, account status)
- Web search for information not present in the internal index
- Computation tools for tasks that require numerical processing rather than language understanding
The retrieval strategy becomes dynamic and source-aware rather than fixed to a single vector search pattern.
The Tradeoffs
Agentic RAG's advantages come with real engineering costs.
Latency increases because multi-step reasoning adds multiple LLM calls and retrieval operations to each user request. For latency-sensitive applications, this requires careful design: pre-computation where possible, streaming responses to maintain perceived responsiveness, and agent step budgets that cap the number of iterations.
Cost increases because agent reasoning requires more LLM calls per query. At production scale, cost governance is not optional. Token budgets per query, caching of intermediate retrieval results, and routing simpler queries to lighter models are all necessary.
Observability becomes harder because the execution path is non-deterministic. You cannot predict in advance which retrieval steps a given query will trigger. Debugging a poor-quality response requires tracing the full agent execution, not just the final prompt and response.
These costs are real but manageable with proper infrastructure. For enterprise AI systems where output quality and reliability matter, the quality improvement from Agentic RAG justifies the engineering investment.
3. Model Context Protocol: Beyond Retrieval to Native Integration
While Agentic RAG makes retrieval smarter, it still operates within a retrieval-centric model. The AI system pulls context from external sources and reasons about it. The integration is unidirectional: data flows into the model, not between the model and live systems.
The Model Context Protocol (MCP), introduced by Anthropic, changes this at the architectural level.
MCP is an open protocol that standardizes how AI models connect to external systems: tools, databases, APIs, file systems, and business platforms. Instead of each AI application building custom integrations for every external system it needs to interact with, MCP provides a universal interface that any compliant system can implement once and expose to any MCP-compatible AI client.
The analogy is useful: MCP for AI integrations is analogous to what USB was for device connectivity. Before USB, every peripheral required a proprietary connector. After USB, any device could connect to any port. MCP aims to play the same role for AI and enterprise systems.
How MCP Works
MCP defines a client-server architecture:
- MCP Servers are lightweight processes that expose a standardized interface to a specific system: a database, a file system, a SaaS platform, a developer tool. Each server declares what resources it exposes, what tools it provides, and what prompts it can supply.
- MCP Clients are AI applications (IDEs, agents, chat interfaces) that connect to MCP servers to access their capabilities. A client can connect to multiple servers simultaneously, giving the AI access to a rich ecosystem of integrated systems.
The protocol defines three core primitives:
Resources: read access to data from an external system. A GitHub MCP server exposes repository contents as resources. A database MCP server exposes tables and query results. The AI can read these resources as context, similar to retrieved documents in RAG, but through a standardized interface rather than a custom integration.
Tools: write and action capabilities. A GitHub MCP server exposes tools to create pull requests, comment on issues, and push commits. A calendar MCP server exposes tools to create events and check availability. Tools allow the AI to take actions in external systems, not just read from them.
Prompts: pre-built prompt templates that the server exposes for common workflows. A code review server might expose a standard code review prompt that an AI client can invoke with minimal setup.
What MCP Changes About Enterprise AI Integration
Without MCP, connecting an AI system to enterprise data and tools requires building custom integrations for each source: a custom connector to Salesforce, a custom connector to Jira, a custom connector to the internal knowledge base, a custom connector to the inventory system. Each integration has its own authentication model, its own data format, its own error handling.
With MCP, each enterprise system builds an MCP server once. Any MCP-compatible AI client can connect to it. The integration surface shifts from N applications times M data sources (an O(N×M) problem) to N applications plus M data sources (an O(N+M) problem). The same MCP server for Salesforce works with any AI client that speaks MCP.
This changes the economics of enterprise AI integration fundamentally. The cost of connecting AI to a new data source drops from weeks of custom integration work to installing and configuring a compliant MCP server.
MCP vs RAG: Complementary, Not Competing
A common question is whether MCP replaces RAG. It does not. They address different concerns.
RAG solves the problem of grounding LLM responses in specific documents or corpus content. Vector search and retrieval are the right mechanism when you need semantic matching over a large document collection: internal documentation, support knowledge bases, research corpora.
MCP solves the problem of connecting AI to live systems with structured interfaces: databases that require exact queries, APIs that require authentication and formatted requests, tools that need to take actions rather than just retrieve information.
In a mature enterprise AI architecture, they coexist:
- RAG handles retrieval from unstructured or semi-structured knowledge bases
- MCP handles integration with structured systems, live data sources, and action-taking tools
- Agentic RAG governs the reasoning layer that decides when to use which approach
4. The Evolution in Production: What It Looks Like
The trajectory from traditional RAG to Agentic RAG to MCP is not a replacement sequence. Each layer adds capability without obsoleting what came before.
A customer support AI might use traditional RAG to retrieve relevant support documentation, Agentic RAG to handle multi-step troubleshooting flows that require iterative information gathering, and MCP to read the customer's account status from the CRM and create support tickets in Jira, all within a single interaction.
An internal engineering assistant might use RAG to search the internal code documentation, Agentic RAG to answer questions that require synthesizing information from multiple documents, and MCP to read live repository state from GitHub, query the CI status API, and create pull requests directly.
An enterprise data analyst might use Agentic RAG to iteratively gather context across multiple knowledge bases and use MCP to execute SQL queries against the data warehouse, retrieve live metrics from the analytics platform, and export results to a report.
The pattern is consistent: RAG for knowledge retrieval, Agentic RAG for intelligent reasoning over that retrieval, MCP for live system integration and action execution.
5. What Engineering Leaders Should Prioritize
Start with retrieval quality, not model size. Whether you are implementing traditional RAG or Agentic RAG, the quality of the retrieval infrastructure determines output quality more than the model. Invest in embedding strategy, hybrid search, index freshness, and re-ranking before upgrading models.
Build evaluation infrastructure before going to production. Agentic RAG and MCP-enabled systems are significantly harder to evaluate than traditional RAG because execution paths are non-deterministic. Golden datasets, automated evaluation pipelines, and output quality monitoring are prerequisites for production deployment, not post-launch additions.
Design for cost from the start. Agentic RAG multiplies LLM calls per query. MCP tool use adds API calls. At production scale, per-query cost governance, caching strategies, and model routing based on query complexity are not premature optimizations. They are survivability requirements.
Adopt MCP where it reduces integration complexity. MCP's primary value is reducing the O(N×M) integration burden. Prioritize MCP adoption for the enterprise systems your AI applications need to access most frequently, and build new internal tools as MCP-compliant servers from the start.
Invest in agent observability. Agentic systems require distributed tracing across agent steps, retrieval operations, and tool invocations. Standard APM tools were not designed for this execution model. Purpose-built observability for agent workflows is a non-optional infrastructure investment.
Conclusion
Traditional RAG solved the knowledge grounding problem. Agentic RAG solved the retrieval reasoning problem. MCP is solving the enterprise integration problem.
These three layers together represent a coherent architecture for production AI systems that need to reason, retrieve, and act across the full complexity of an enterprise environment.
The distinction matters because teams that build on only one layer consistently hit the ceiling of that layer. Static retrieval pipelines fail at complex multi-hop queries. Intelligent retrieval without live system integration cannot take action. Custom integrations without a standardized protocol become maintenance burdens that slow every subsequent expansion.
The enterprise AI systems that will define the next decade are being built on all three layers simultaneously, with the engineering rigor that distributed systems infrastructure has always required.
At JMS Technologies Inc., we design and build AI platforms across the full retrieval and integration stack, combining RAG architecture, agentic reasoning, and MCP-based enterprise integration to deliver systems that are intelligent, connected, and built to scale.
Designing enterprise AI infrastructure that needs to go beyond static retrieval? Let's talk.