How Uber Handles 1M+ Requests per Second to Find Nearby Drivers

- Published on
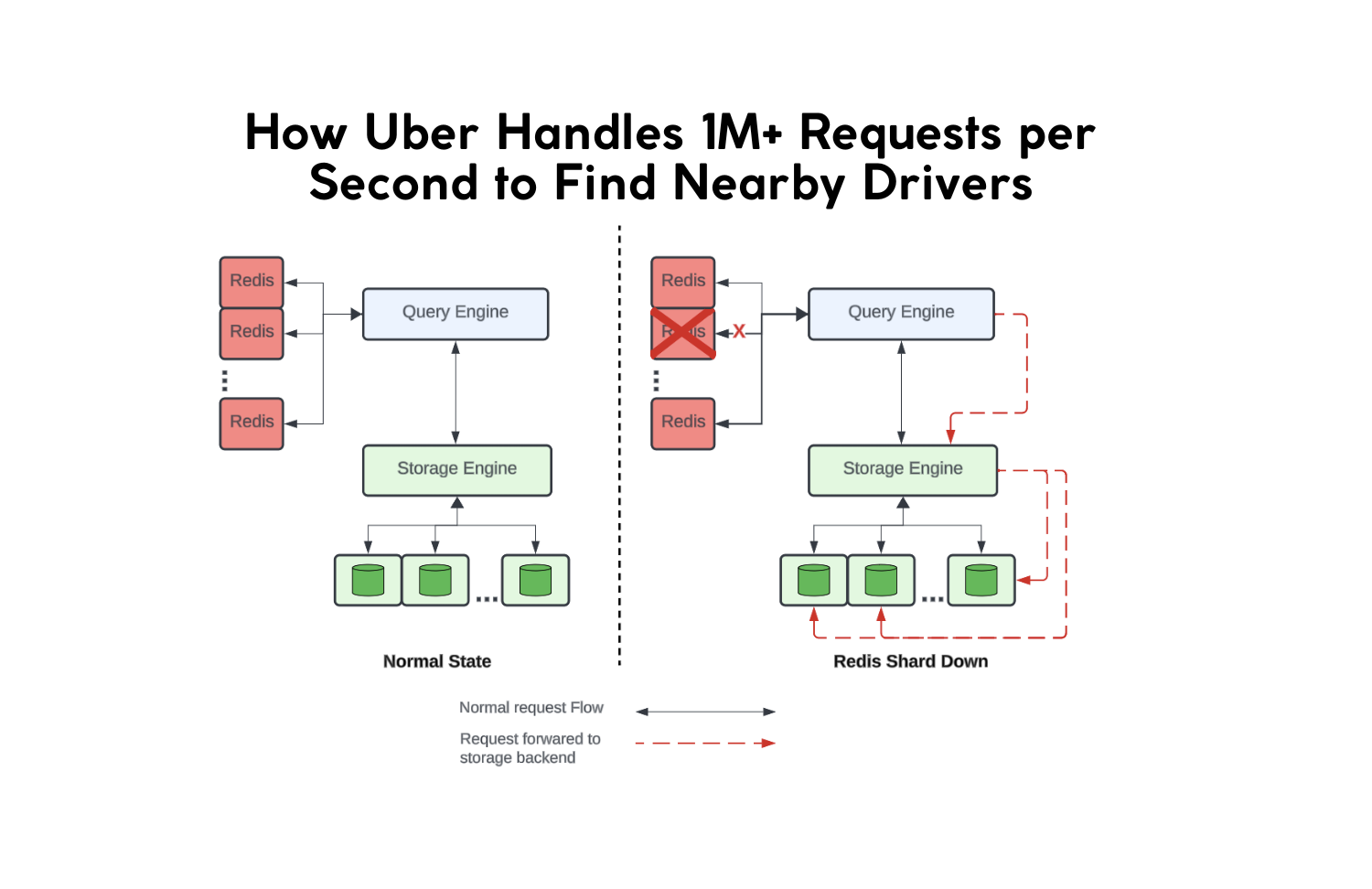
Understanding how Uber handles more than 1,000,000+ geospatial requests per second to find nearby drivers is one of the clearest examples of modern real-time distributed systems engineering.
From the outside, the app looks simple:
You open the app, tap a button, and nearby drivers appear instantly.
Under the hood, it’s a global-scale system handling:
- millions of moving data points
- geospatial indexing
- event-driven pipelines
- real-time matching
- low-latency lookup
- massive concurrency
This article breaks down exactly how Uber’s architecture works, from H3 indexing to streaming pipelines to the modern batched matching engine, and what senior engineers can learn from it.
1. The Real Challenge: Massive Real-Time Geospatial Computation
Before payments, dispatch, surge, or routing, Uber’s core challenge is:
Maintaining a fresh, accurate global map of all drivers in real time.
Drivers send location updates every 2–4 seconds, generating millions of GPS coordinates per minute. These updates must be:
- ingested
- cleaned
- validated
- indexed
- stored in memory
- made available instantly
Unique challenges:
High cardinality
Every driver is an independent, constantly moving object.
Volatile state
Locations lose value within seconds.
Ultra-low latency (< 200 ms)
Perceived app performance depends on geospatial response time.
Extreme parallelism
Major metro areas generate dense, simultaneous request spikes.
This instantly eliminates:
- PostGIS queries
- relational geospatial searches
- per-request Haversine distance calculations
- blocking request/response pipelines
- disk-based operations
To scale globally, Uber must keep its entire hot path in memory and event-driven, avoiding expensive calculations entirely.
2. H3: The Hexagonal Geospatial Index That Makes Uber Scale
To efficiently partition the world, Uber built H3, a hexagonal hierarchical grid system.
Why hexagons?
- Uniform neighbor geometry
- Less distortion vs. square grids
- Efficient k-ring expansion for radius searches
- Naturally supports hierarchical zoom levels
How the driver location pipeline works
- Driver sends GPS coordinates.
- Coordinates → converted into an H3 cell.
- Each H3 cell stores an in-memory set of available drivers.
- Cells are organized into metro-area shards.
- When a rider requests a trip, the backend queries only the relevant cells.
Instead of “finding nearby drivers” using computation, Uber does:
O(1) memory lookups on targeted H3 cells.
This transforms a once-impossible geospatial problem into a near-zero-latency operation.
3. Streaming, Not Request/Response: Uber’s Real Architecture
Most apps rely on:
Client → API → DB → Response
Uber cannot.
Every driver and rider continuously emits events, feeding a massive real-time streaming backbone.
Key components:
- Kafka / uReplicator for ingestion and fan-out
- Real-time geospatial microservices (Go/Java)
- Distributed in-memory key-value stores
- Persistence only for analytics (Spanner / Docstore)
Nothing critical touches disk in the hot path.
This means:
- no joins
- no heavy queries
- no synchronous DB lookups
Just constant streaming updates, producing a consistent snapshot of the world.
4. Matching: From Naive Nearest Driver to Global Optimization
Originally, Uber assigned riders to the nearest driver.
Simple, but flawed at scale:
- convoy effects
- hotspots with overloaded drivers
- suboptimal ETAs
- inefficient city-wide assignment
Modern Uber uses Batched Matching, a far more advanced algorithm.
Batched matching steps:
- Collect rider and driver states for 2–5 seconds.
- Build a bipartite graph (riders ↔ drivers).
- Run min-cost / max-flow optimization.
- Compute global optimal assignments.
- Dispatch instantly.
Why this works better:
- optimal global allocation
- fewer missed trips
- smoother ETAs
- more balanced supply/demand
H3 provides the candidate sets.
The matching engine chooses the optimal assignment.
5. Why Uber Scales to Over 1M+ Requests per Second
It’s not about server count. It's about architectural principles.
a) Geographic Sharding
Cities behave like independent systems.
A London surge never affects LA.
b) Hyperlocal L1/L2 Caching
Geo-caches per metro area dramatically reduce latency and improve p99/p999.
c) Backpressure & Load Shedding
Uber protects the system by:
- dropping stale events
- prioritizing fresh updates
- slowing downstream consumers
This prevents cascading failures.
d) Circuit Breakers Everywhere
If a subsystem fails:
- circuit opens
- system returns degraded-but-valid data
- global outages are avoided
e) True Horizontal Autoscaling
Across:
- microservices
- event pipelines
- geospatial caches
- H3 shards
Almost nothing scales vertically.
6. Practical Lessons for Engineers Building Real-Time Systems
These principles generalize to any high-frequency application.
1. Real performance comes from data modeling
Not databases.
Not indexes.
Data modeling is the real performance multiplier.
2. For high-frequency data, event-driven > request/response
Polling and synchronous calls don’t scale.
3. Hot-path data must live in memory
Disk = analytics.
Memory = real-time.
4. Precompute aggressively
Fast systems compute before the request.
5. Shard using real-world logic
Geography, supply/demand zones, human behavior patterns.
6. Assume everything will fail
Backpressure, retries, circuit breakers, and failure isolation must be first-class citizens.
7. Final Summary: Why Uber’s Architecture Works
Uber can handle 1M+ “nearby driver” lookups per second because the architecture is:
- local-first
- in-memory
- geo-sharded
- event-driven
- heavily precomputed
The platform avoids expensive geospatial computation entirely.
Instead, it relies on:
- efficient data modeling
- H3 hex-based indexing
- massive streaming pipelines
- global optimization algorithms
This transforms an impossible engineering problem into a system capable of delivering sub-200 ms responses at global scale.
At JMS Technologies Inc., we apply these same principles when designing real-time, high-scale architectures for our clients.
Building a real-time system or on-demand platform?
We can help you architect it for millions (or billions) of users.