Why AI Needs GPUs and TPUs: The Hardware Behind Modern Machine Learning

- Published on
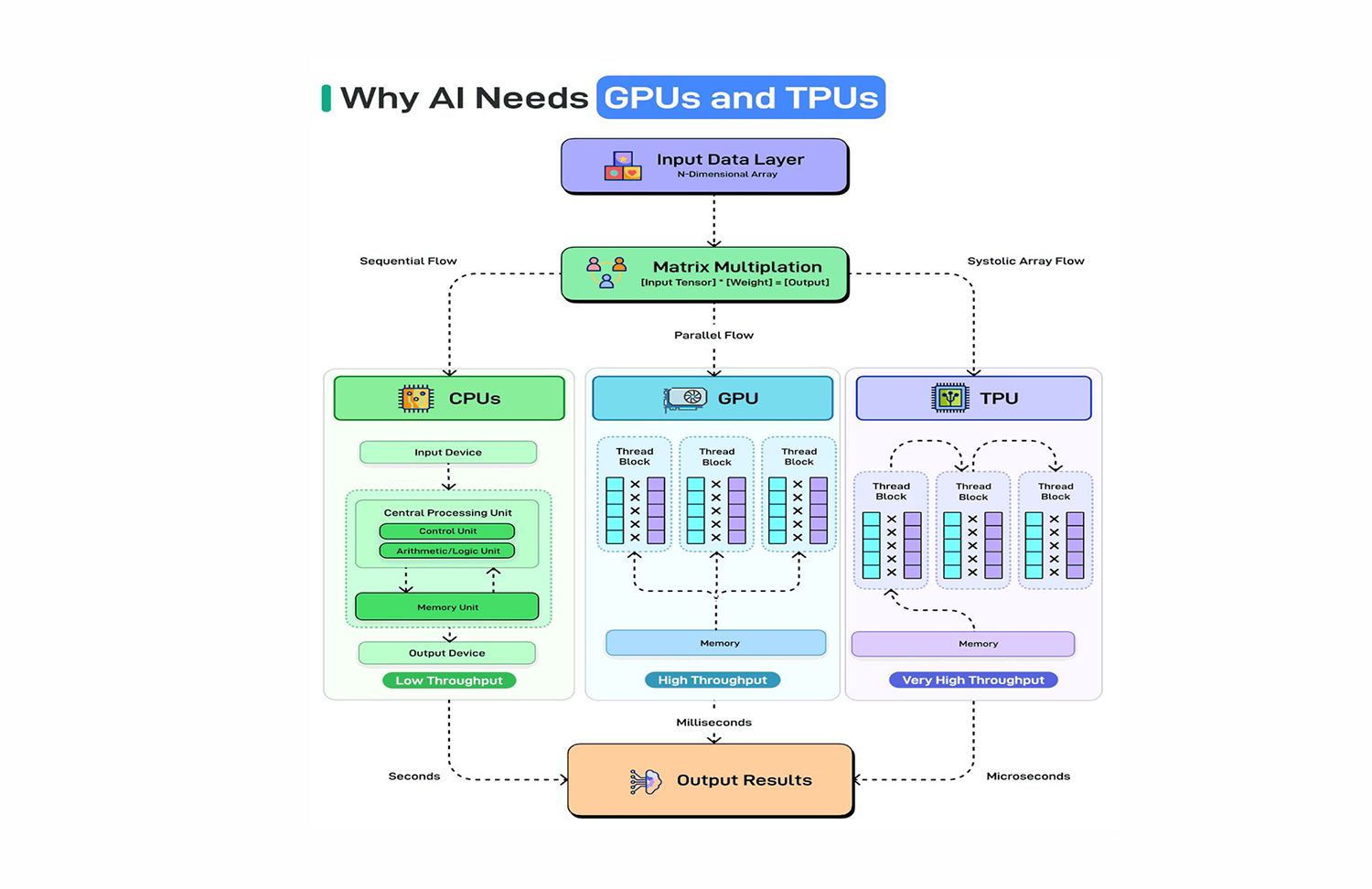
Modern AI is not a software-only revolution. It is a hardware-software co-design story, and understanding the hardware side is critical for any engineering leader making decisions about AI infrastructure, cost, and performance.
Training GPT-4-scale models required thousands of specialized chips running in parallel for months. Inference at production scale demands hardware purpose-built for one task: multiplying enormous matrices as fast as physically possible.
To understand why, you need to understand what AI actually does at the metal level, and why the CPU, despite decades of engineering excellence, is fundamentally the wrong tool for the job.
1. What AI Actually Does: Math at Inhuman Scale
Strip away the abstractions: the layers, the attention heads, the embeddings. At its core, a neural network is a sequence of matrix multiplications.
Given an input vector x and a weight matrix W, a single layer computes:
output = activation(W · x + b)
A transformer model like GPT-3 has 175 billion parameters. During a forward pass, the model executes billions of multiply-accumulate operations across matrices with millions of elements.
During training, you do this forward pass, compute a loss, and then backpropagate gradients through every layer. Across a dataset with trillions of tokens, repeated for hundreds of thousands of steps.
This is not a control flow problem. There are no if statements to branch on. No pointer chasing through memory. Just the same primitive operation: multiply, accumulate, activate. Executed at a scale that no general-purpose processor was designed for.
2. Why CPUs Hit a Wall
CPUs are architectural marvels optimized for sequential, latency-sensitive workloads.
A modern CPU core executes instructions via a deeply pipelined process:
- Fetch → retrieve the next instruction from instruction cache
- Decode → interpret what the instruction means
- Execute → perform the operation in the ALU or FPU
- Write-back → store the result to a register or memory
This pipeline is fast. Modern CPUs execute billions of instructions per second. But AI workloads expose its fundamental weakness: memory bandwidth.
The bottleneck is not compute. It is the constant shuttling of data between DRAM, L3 cache, L2 cache, L1 cache, and registers to feed that execution pipeline. For large matrix operations, the processor stalls waiting for data, a phenomenon called memory-bound execution.
Worse, CPUs have between 4 and 128 cores. For a matrix multiplication requiring 100 billion operations, parallelism across 64 cores is still orders of magnitude insufficient.
Think of it this way: a CPU is a Ferrari. Extremely fast for one car on an empty road. But you need to move a million passengers simultaneously. A Ferrari is the wrong vehicle entirely.
3. GPUs: Parallel Processing at Scale
The Graphics Processing Unit was originally designed to render pixels, a task that is embarrassingly parallel. Each pixel on a 4K screen can be computed independently. To render 8 million pixels at 60fps, you need massive parallelism, not raw single-core speed.
NVIDIA recognized in the early 2000s that this same architecture was ideal for scientific computing. Their CUDA platform (released 2007) opened GPUs to general-purpose computation, and the deep learning community seized on it.
Why GPUs Excel at AI Workloads
A modern NVIDIA H100 GPU has 16,896 CUDA cores, each capable of executing floating-point operations simultaneously. Compare this to the 16–128 cores in a high-end CPU.
For matrix multiplication, the dominant operation in neural networks, this architecture is transformative:
Matrix A (1024 x 1024) × Matrix B (1024 x 1024)
= ~2.1 billion multiply-accumulate operations
CPU (64 cores): ~minutes at full utilization
GPU (16,896 cores): ~milliseconds
GPUs also feature High Bandwidth Memory (HBM), memory stacked directly on the GPU die, delivering terabytes per second of bandwidth. The H100 provides 3.35 TB/s of memory bandwidth, compared to ~100 GB/s on a high-end CPU.
This eliminates the memory bottleneck that cripples CPUs on large-matrix workloads.
Key GPU Architectural Properties for AI
- SIMD execution (Single Instruction, Multiple Data): all cores execute the same instruction on different data simultaneously, ideal for vectorized matrix ops
- Tensor Cores: dedicated hardware units on NVIDIA Ampere/Hopper that perform 4×4 matrix multiplications in a single clock cycle
- NVLink: high-speed GPU-to-GPU interconnects allowing multi-GPU training with minimal communication overhead
- Mixed precision: FP16/BF16 computation with FP32 accumulation, doubling throughput while maintaining numerical stability
The result: training workloads that would take weeks on CPU clusters complete in hours or days on GPU clusters.
4. TPUs: Hardware Built Exclusively for Machine Learning
If GPUs are general-purpose parallel processors repurposed for AI, TPUs are the opposite: hardware designed from first principles for machine learning.
Google developed the Tensor Processing Unit internally in 2015 and deployed it in production to serve Google Search, Translate, and Photos before publishing details publicly in 2017. The motivation was direct: deploying neural networks at Google's inference scale on GPUs was too expensive.
The Systolic Array Architecture
The TPU's defining design is the systolic array, a grid of multiply-accumulate (MAC) units wired together so that data flows through the array rhythmically, like a heartbeat.
Data flows →
Weight flows ↓
[MAC] → [MAC] → [MAC] → [MAC]
↓ ↓ ↓ ↓
[MAC] → [MAC] → [MAC] → [MAC]
↓ ↓ ↓ ↓
[MAC] → [MAC] → [MAC] → [MAC]
Each MAC unit:
- Multiplies the incoming input activation by a locally stored weight
- Accumulates the result into a running partial sum
- Passes the input to the next unit in the row
- Passes the partial sum to the next unit in the column
This design makes matrix multiplication extraordinarily efficient because:
- Data reuse is maximized: each weight is used by multiple activations as they flow through
- Memory transfers are minimized: intermediate results stay inside the array, not in DRAM
- Control logic is eliminated: the dataflow is deterministic, so no branch prediction or out-of-order execution overhead
The TPU v1 achieved 92 TOPS (tera-operations per second) at INT8 precision, approximately 15–30× better performance per watt than a contemporary GPU for inference workloads.
TPU v4 and Beyond
Modern TPUs have evolved dramatically:
- TPU v4: 275 TFLOPS BF16, connected in 4096-chip pods via high-radix optical interconnects
- TPU v4 pod: 1.1 exaFLOPS of BF16 compute in a single datacenter rack cluster
- Optimized for transformers: matrix layout, tiling strategies, and memory hierarchy are co-designed with model architectures like BERT and PaLM
Google trained PaLM (540B parameters) on 6144 TPU v4 chips. The infrastructure (hardware, networking, compiler XLA, and model) was designed as a unified system.
5. GPU vs TPU: Engineering Trade-offs
Neither is universally superior. The right choice depends on your workload, team, and ecosystem.
| Dimension | GPU (NVIDIA H100) | TPU (v4) |
|---|---|---|
| Flexibility | High, supports any framework | Lower, optimized for JAX/TF |
| Ecosystem | Mature (PyTorch, CUDA, TensorRT) | Google-centric |
| Training efficiency | Excellent | Excellent (edge for LLMs) |
| Inference latency | Good with TensorRT optimization | Very good for batch inference |
| Memory bandwidth | 3.35 TB/s | ~2.7 TB/s per chip, but interconnect scales differently |
| Availability | AWS, GCP, Azure, bare metal | GCP only |
| Custom ops | Full CUDA custom kernels | Limited, XLA must handle it |
When to choose GPU:
- PyTorch-first teams
- Custom CUDA kernel requirements
- Research flexibility over production efficiency
- Multi-cloud or on-prem deployments
When to choose TPU:
- JAX-based training pipelines
- Very large LLM training on GCP
- Cost efficiency at Google-scale inference
- Tight XLA/Jax integration
6. The Deeper Principle: Hardware-Software Co-Design
The most important lesson from GPU and TPU architecture is not about specific chips. It is about co-design.
The transformer architecture was not invented in a vacuum. It was invented by researchers who knew they had GPUs with specific memory hierarchies, bandwidth profiles, and parallelism properties. Attention mechanisms are parallelizable across sequence positions, by design.
When Google built TPUs, they didn't just optimize existing GPU workloads. They redesigned the compiler (XLA), the numerical formats (BF16), the interconnect topology, and the programming model, all in concert with the models they were training.
This is why FlashAttention matters: it's an attention algorithm redesigned around GPU memory hierarchy (SRAM vs HBM), reducing memory I/O by an order of magnitude. Not a model change. Not a hardware change. A co-design that makes both more efficient together.
The engineers who will build the next generation of AI systems are the ones who understand both sides of this boundary.
7. Practical Implications for Engineering Leaders
Infrastructure decisions have 10× cost leverage. Choosing the right instance type (A100 vs H100 vs TPU v4) for your workload can mean the difference between $100K and $1M in training costs.
Model architecture and hardware must be considered together. Deploying a model with large batch sizes on TPUs can be dramatically cheaper than small-batch GPU inference. Profile your inference patterns before committing to hardware.
Quantization is not optional at scale. INT8/INT4 quantization on GPU Tensor Cores or TPU INT8 units delivers 2–4× throughput gains for inference with acceptable accuracy loss. This is table stakes for production AI.
Interconnect is the hidden bottleneck in large-scale training. As models grow beyond a single GPU's memory, you enter the regime of model parallelism: tensor parallel, pipeline parallel, expert parallel. The performance of your NVLink, InfiniBand, or TPU ICI interconnect becomes the actual constraint.
Compilation matters. torch.compile, TensorRT, and XLA all transform computation graphs for specific hardware targets. Skipping compilation means leaving 20–60% performance on the table.
Conclusion
AI progress is inseparable from hardware progress. The transformer revolution was possible not just because of the attention mechanism, but because GPUs existed to make it practical to train at scale.
GPUs deliver massive parallelism through thousands of CUDA and Tensor Cores, eliminating the memory bandwidth bottleneck that makes CPUs impractical for large matrix workloads.
TPUs take this further: purpose-built systolic arrays that maximize compute per watt by co-designing the data flow with the math of neural networks itself.
Understanding this hardware layer is not optional for senior engineers. It is the difference between building AI systems that are efficient, scalable, and economically viable versus ones that are unnecessarily expensive, slow, or brittle under production load.
At JMS Technologies Inc., we design AI infrastructure across GPU and TPU platforms, helping engineering teams make hardware-aware architecture decisions from training pipelines to production inference systems.
Designing AI infrastructure at scale? Let's talk.