How X/Twitter’s Timeline Architecture Works at Planetary Scale

- Published on
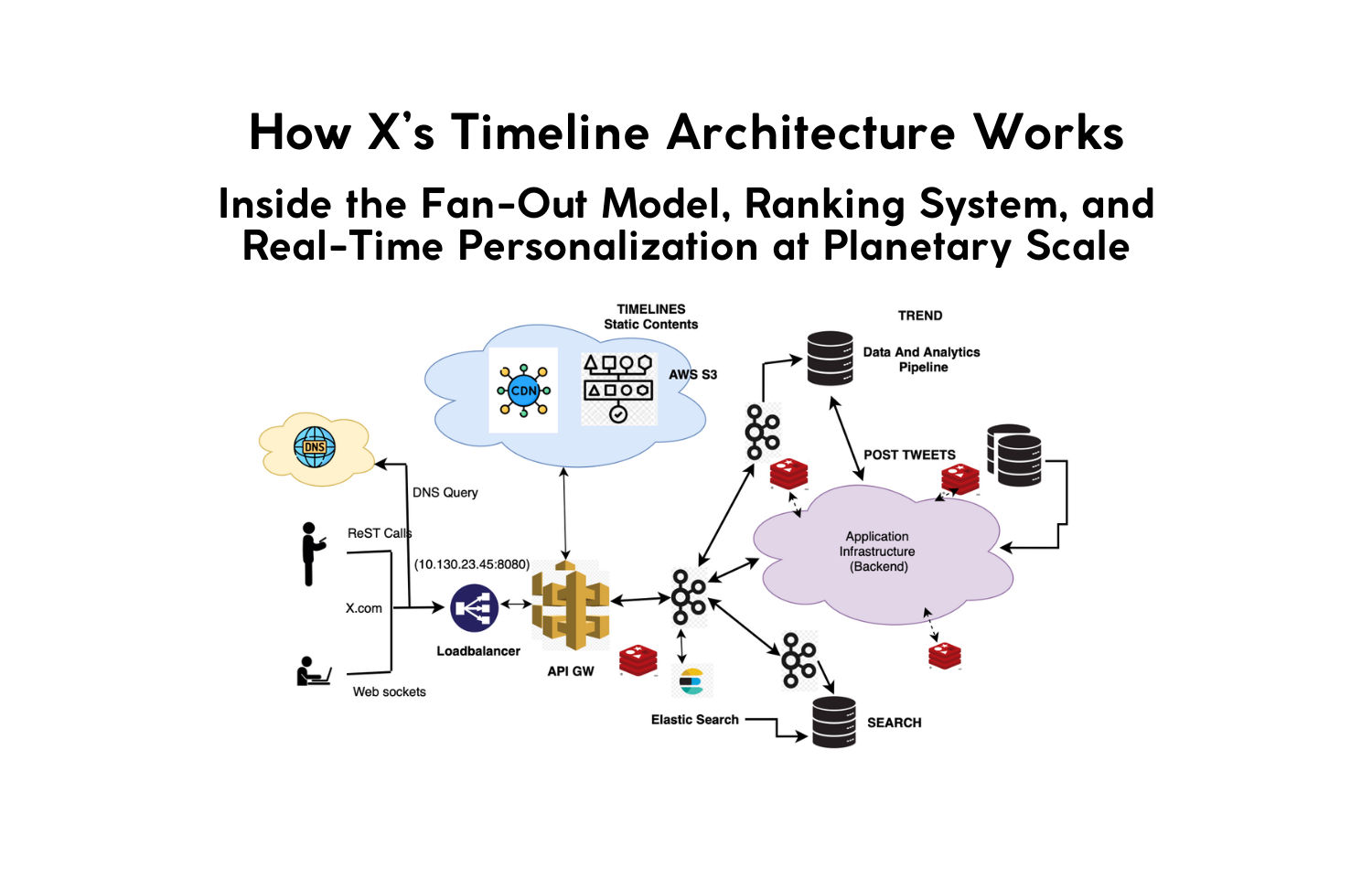
Understanding how X (formerly Twitter) builds and serves its timeline is one of the most instructive examples of large-scale system design. While the company originally built a near-real-time social feed, X is now evolving toward a broader vision, an "Everything App" with video, long-form posts, payments, creators, and AI-driven discovery.
At the center of this ecosystem is the "For You" timeline, a personalized, ML-driven feed supported by a distributed architecture capable of processing millions of events per second.
For CTOs, staff engineers, and systems architects, analyzing how X’s timeline works reveals powerful lessons in distributed systems, high-throughput data pipelines, ranking models, and large-scale fault tolerance.
1. From Twitter to X: Why the Architecture Matters Even More Now
The rebrand to X wasn’t just cosmetic, it's tied to a deeper product transformation. X is no longer only a microblogging platform. It is integrating video streaming, shopping, payments, audio spaces, long-form media, creator monetization, and AI agents.
This means the timeline must handle more content types, more ranking dimensions, and more real-time signals than ever before.
Yet the core engineering challenge remains the same:
Deliver a highly personalized timeline under strict latency constraints, with global consistency, while handling unpredictable load patterns.
This is where X’s original architecture, built for massive fan-out, becomes even more critical.
2. Fan-Out on Write: The Backbone of X’s Scaling Strategy
The fundamental architectural principle remains a Fan-Out on Write approach, optimized for speed and real-time delivery.
How It Works
When a user posts on X, the system immediately pushes the post ID to the home timelines of their followers. This minimizes read cost later, enabling:
- Low latency timeline loads
- Predictable read performance
- Consistently updated feeds
- Fast reactions to trending events
The system utilizes Manhattan (X’s distributed database), RocksDB-backed fan-out workers, and distributed queues to handle write amplification.
The "Celebrity Problem": Hybrid Handling
X uses a hybrid model for accounts with millions of followers (e.g., Elon Musk, MrBeast).
- Standard Users: Push to all followers on write.
- High-Fanout Users: Instead of writing to millions of timelines (which causes write latency spikes), their posts are inserted on read.
This hybrid architecture prevents "thundering herd" problems and is essential for handling viral moments without taking down the write pipeline.
3. The Write Pipeline in X: Faster, Heavier, More Complex
Compared to the Twitter era, X’s write path now handles significantly more complexity:
- Heavy media content (4K video)
- Longer posts (up to 25K+ characters)
- Cash tags and commerce metadata
- AI-generated summaries and Grok integration
The Core Flow
- API Gateway: Routes the request.
- Post Service: Handles validation, anti-spam, metadata extraction, and creator tags.
- Content Storage: * Metadata goes to entity stores.
- Media assets go to dedicated video/image pipelines.
- Fan-Out Queue: Massive distributed queues push updates to follower timelines.
- Home Timeline Shards: Append-only structures optimized for extremely fast sequential writes.
- Ranking Metadata Injection: Signals like watch time probability and intent modeling are tagged during write-time to aid downstream ranking.
4. The “For You” Timeline: Modern Ranking and ML Pipelines
The timeline is no longer simply a stream of tweets; it’s a multi-source, multi-modal feed.
The Hydration Pipeline
When a user opens X, the system must execute a complex orchestration in milliseconds:
- Fetch the precomputed home timeline.
- Pull candidates from the "For You" recommendation engine (Out-of-Network sources).
- Inject monetized content, ads, and interest cluster data.
- Filter based on visibility rules (mutes, blocks).
- Re-rank using heavy ML models.
Modern ML Stages
X uses a sophisticated funnel to narrow down millions of posts to the dozen you see on screen:
- Candidate Generation: Retrieve 1,500–3,000 potential posts from In-Network (people you follow) and Out-of-Network (vector embeddings/similars).
- Light Ranking: Quick heuristics and relevance checks to discard low-quality content.
- Heavy Ranking: Deep learning models evaluating:
- Engagement prediction (Likelihood to Like/Reply)
- Watch time estimation (Video retention)
- User affinity graphs
- Safety boundaries (NSFW detection)
- Post-Ranking: Recency balancing, diversity rules (don't show 10 tweets from the same author), and cluster separation.
5. Storage, Caching, and Throughput Improvements
Since 2023, X Engineering has reworked large parts of the stack to improve efficiency and reduce cloud costs.
- Home Timeline Store: High-throughput append-only tweet ID storage.
- Graph Store: Optimized for rapidly changing relationships (subscriptions, paid verification boosts).
- Tweet/Post Store: Expanded support for long-form and media-heavy content.
- Redis / Memcache: Used aggressively for hot posts, timeline caches, and ranking inference memoization.
Why Caching Matters More at X Scale
Video and long-form content drastically increase compute and storage costs. Multilevel caching is now mandatory to avoid blowing up inference budgets when serving millions of concurrent reads.
6. Fault Tolerance: Designing for Failure
Given X’s aspiration to serve critical infrastructure, graceful degradation is essential. The system employs several "dark modes":
- Ranking Fallback: If the heavy ranker is overloaded, serve the timeline in reverse-chronological order.
- Fan-out Degradation: If queues back up, slow down background delivery rather than dropping data.
- Celebrity On-Read: Dynamically switch high-velocity accounts to pull-based models during viral spikes.
- Cold Cache Fallback: Serve older cached timelines if the primary storage layer is unresponsive.
7. What CTOs and Engineering Leaders Can Learn
The evolution from Twitter to X highlights strategic design principles applicable to any high-scale platform:
- Precompute Whenever Possible: Real-time systems break down under heavy read loads. Precomputation enables stable, predictable latency.
- Segment Ranking into Layers: Using a funnel (Light → Heavy → Post-ranking) makes it easier to control inference costs and latency.
- Architect for Edge Cases: High-fanout accounts and viral content need special routing; one size does not fit all.
- Embrace Hybrid Models: Pure "Push" or pure "Pull" architectures are rarely optimal at scale.
- Design for Degradation: Build systems that fail gracefully into a "degraded but functional" state rather than crashing completely.
Conclusion
As X transitions into a broader “Everything App,” its timeline architecture becomes even more central to product scalability. By combining precomputed home timelines, ML-driven ranking pipelines, and high-throughput distributed systems, X achieves real-time personalization for hundreds of millions of users.
Understanding these systems provides engineers with deep insights into how to build scalable feeds, recommendation engines, and real-time distributed systems capable of supporting massive workloads.
At JMS Technologies Inc., we apply these exact high-scale principles when architecting platforms for our enterprise clients.
Need to architect a system for massive scale? Let’s talk.