How YouTube Scaled to 2.49 Billion Users Using MySQL (and Later Vitess)

- Published on
Understanding how YouTube scaled to billions of users using MySQL, and later Vitess, is one of the most instructive examples of real-world distributed systems engineering.
When a technical team hears that YouTube, one of the largest platforms ever created, originally ran its core architecture on MySQL, the reaction is predictable:
“How can a relational database power a platform with 2.49 billion users?”
The truth is far more interesting: YouTube didn’t scale in spite of MySQL, it scaled around MySQL, using aggressive sharding, global replication, multi-layer caching, and eventually Vitess, the database-virtualization layer Google built to scale MySQL to planetary levels.
For CTOs, staff engineers, and systems architects, YouTube’s evolution offers deep lessons on database scaling, metadata-heavy workloads, and designing systems that survive world-level traffic.
1. Why YouTube Started With MySQL: The Right Tool at the Right Time
When YouTube launched in 2005, the goal was speed of execution. MySQL provided:
- Simplicity
- Maturity
- A familiar developer ecosystem
- Low cost
- A reliable transactional model for metadata
Critically, MySQL did not store video content, only metadata such as:
- Video ID
- Channel owner
- Title, tags, descriptions
- Visibility & permissions
- Basic user & channel information
This dataset was:
- Lightweight
- Highly indexed
- Read-heavy
- Perfect for relational modeling
Why Not Oracle or NoSQL?
In 2005:
- NoSQL systems like Cassandra, DynamoDB, and MongoDB didn’t exist yet.
- Oracle was:
- expensive,
- slow to deploy,
- and difficult to scale horizontally.
MySQL was simply the practical choice for a fast-moving startup.
2. The Core Scaling Problem: Billions of Reads, Millions of Writes
YouTube’s growth created a distinct load pattern:
- Massive reads, every video view requires metadata
- Moderate writes, uploads, comments, likes
- Extreme concurrency
- Global, low-latency requirements
In other words, object storage for videos wasn’t the bottleneck, metadata lookups were.
The true challenge was ensuring each metadata query returned in milliseconds, even during global traffic spikes.
3. Manual Sharding: YouTube’s First Real Scaling Strategy
Before Vitess existed, sharding was entirely manual.
The team implemented simple but highly effective methods:
Sharding by Video ID
Each ID range mapped to a shard:
- Shard A: 0–9M
- Shard B: 9–18M
- Shard C: 18–27M
This distributed load evenly without complex migrations.
Sharding by User and Channel
User profiles, subscriptions, and channel metadata were also partitioned.
How the Application Routed Queries
Routing lived inside:
- Python application logic
- A custom middle tier
- Static configuration maps
Crude but effective, this alone allowed YouTube to scale far beyond most startups of its time.
4. Replication at Massive Scale: Handling Global Read Traffic
YouTube relied heavily on a classic high-scale pattern:
1 primary → many read-only replicas
Why?
Metadata requests outweigh writes by several orders of magnitude.
With replicas distributed worldwide:
- Global latency dropped
- Traffic spikes became manageable
- Primaries focused on consistent writes
The Limitations
Old MySQL replication suffered from:
- Asynchronous replication lag
- Painful failover processes
- Inconsistency during peak load
These issues became part of the motivation behind building Vitess.
5. Caching: The Real Secret Behind YouTube’s Performance
Even early on, YouTube understood that MySQL should not serve most requests.
They implemented aggressive caching layers:
Memcached Layer
Frequently-requested metadata lived in RAM.
Latency: sub-millisecond.
CDN + HTTP Caching
Thumbnails, static pages, and cacheable metadata responses were distributed globally.
Cache-Aside Pattern
YouTube relied heavily on this approach:
Check cache → if miss → hit database → store in cache.
In practice, over 80% of metadata requests never touched MySQL.
Caching was foundational, not an optimization.
6. Offloading Heavy Workloads After the Google Acquisition
After joining Google, YouTube moved heavy analytics to specialized distributed systems.
BigTable for Global Statistics
Perfect for high-volume, low-latency key-value access:
- View counts
- Engagement metrics
- Per-region statistics
GFS/Colossus for Logs
Playback logs, events, and massive telemetry streams lived in Google’s distributed file system.
MapReduce for Batch Processing
Used for:
- Trending video detection
- Spam and abuse filtering
- Aggregated metrics
- Recommendation inputs
This offloaded billions of operations per day away from MySQL.
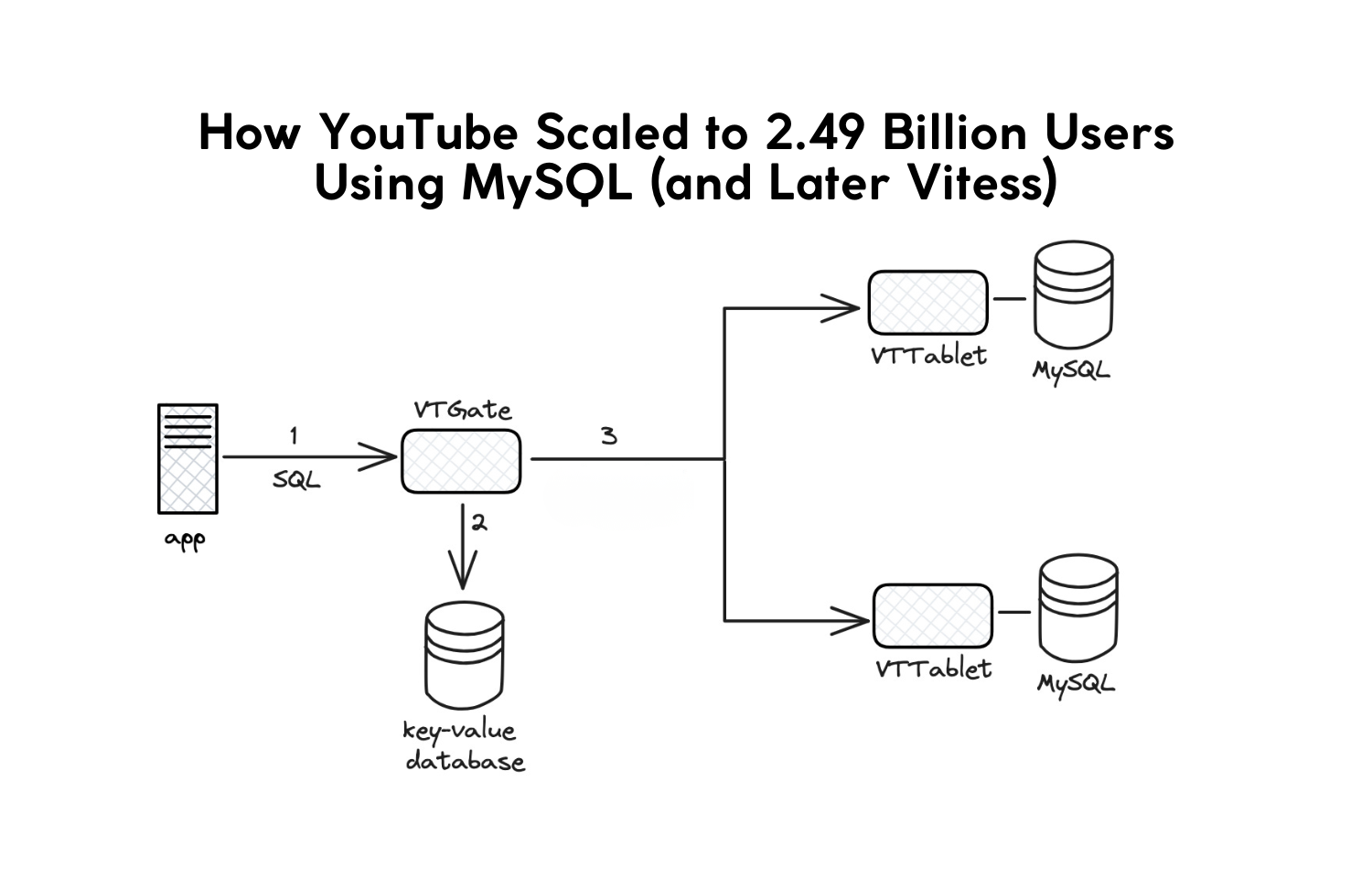
7. Vitess: The Breakthrough That Took YouTube to Planetary Scale
The real inflection point was Google’s creation of Vitess, now one of the most important database technologies in the world.
Vitess provided:
MySQL Virtualization
Vitess acts as a smart proxy that:
- Hides shard topology
- Manages connections
- Routes queries automatically
- Optimizes performance
Developers no longer needed to think about which shard a request lived on.
Live Resharding with Zero Downtime
A game-changing feature:
- Rebalance partitions
- Move data
- Scale horizontally
, all while serving millions of QPS in production.
Horizontal Scaling with ACID Guarantees
Vitess allowed MySQL to scale like NoSQL while preserving SQL features:
- transactions
- indexing
- consistency
- schemas
This combination is why global companies like Slack, Square, GitHub Actions, and Etsy adopted Vitess.
8. What Modern Engineering Leaders Can Learn
YouTube’s architecture offers timeless lessons.
When MySQL Still Makes Sense
Use MySQL if:
- Your data is structured
- Strong consistency matters
- Your workload is read-heavy
- You can cache aggressively
When to Shard
Rule of thumb:
If a single database node starts struggling with CPU, I/O, or concurrency, it’s time to shard.
Early sharding avoids costly rewrites.
When to Adopt Vitess
Vitess is ideal when you need:
- Automatic sharding
- Global replicas
- Zero-downtime resharding
- Multi-million QPS
- Transparent topology management
If you're scaling MySQL beyond a single cluster, Vitess becomes the logical next step.
Conclusion
YouTube’s success didn't come from choosing the “perfect” database, it came from designing the architecture around the database.
By combining:
- manual sharding,
- massive replication,
- heavy caching,
- distributed Google systems,
- and ultimately Vitess,
YouTube transformed MySQL from a traditional relational engine into a database capable of handling planetary-scale traffic.
The lesson is simple:
Databases scale when the architecture around them is designed to scale.
At JMS Technologies Inc., we apply the same high-scale principles when designing systems for our clients.
Need help architecting a platform to handle millions (or billions) of users? Let's talk.